📗 -> 05/12/25: ECS189G-L18
🎤 Vocab
❗ Unit and Larger Context
Starting from RNN Application Examples (Project Stage 4)
✒️ -> Scratch Notes
Project Stage 4 - Hints
Tokenizer - Hugging Face
- Split words into tokens
- Tokens != Words
- Denotes frequent patterns in words
Vectorizer - GloVe: Global Vectors for Word Representations
huggingface - google-bert/bert-case-uncased
Architecture 1
- Given a document (sequence of words)
- Classify it into different classes (pos vs neg)
Use a RNN to go word by word, and generate output at the end: is a sigmoid function
Architecture 2
Same thing, but instead of using RNN at the end:
- Basically, summing the average value throughout the document, not just at the end
Document Generation
What did the bartender say to the jumper cables?
You better not try to start anything . [endtoken]
Perform loss with each subsequent “section”
- What did the ---- -> Predict -> Loss (did they say bartender?)
- What did the bartender ---- -> Predict -> Loss (did they say say?)
- …
Alternatively, generate multiple subsequent words at a time - What did the — — — -> Predict -> Loss (did they say “bartender say to” ?)
Masking Models - Like BERT? proposed by google
- Given one sentence, mask multiple words. Then, use context to predict word
Gradient Vanishing/Exploding
Deep and Long RNN:
- Deep - Stack RNN on each other
- Long - Work on longer sequences
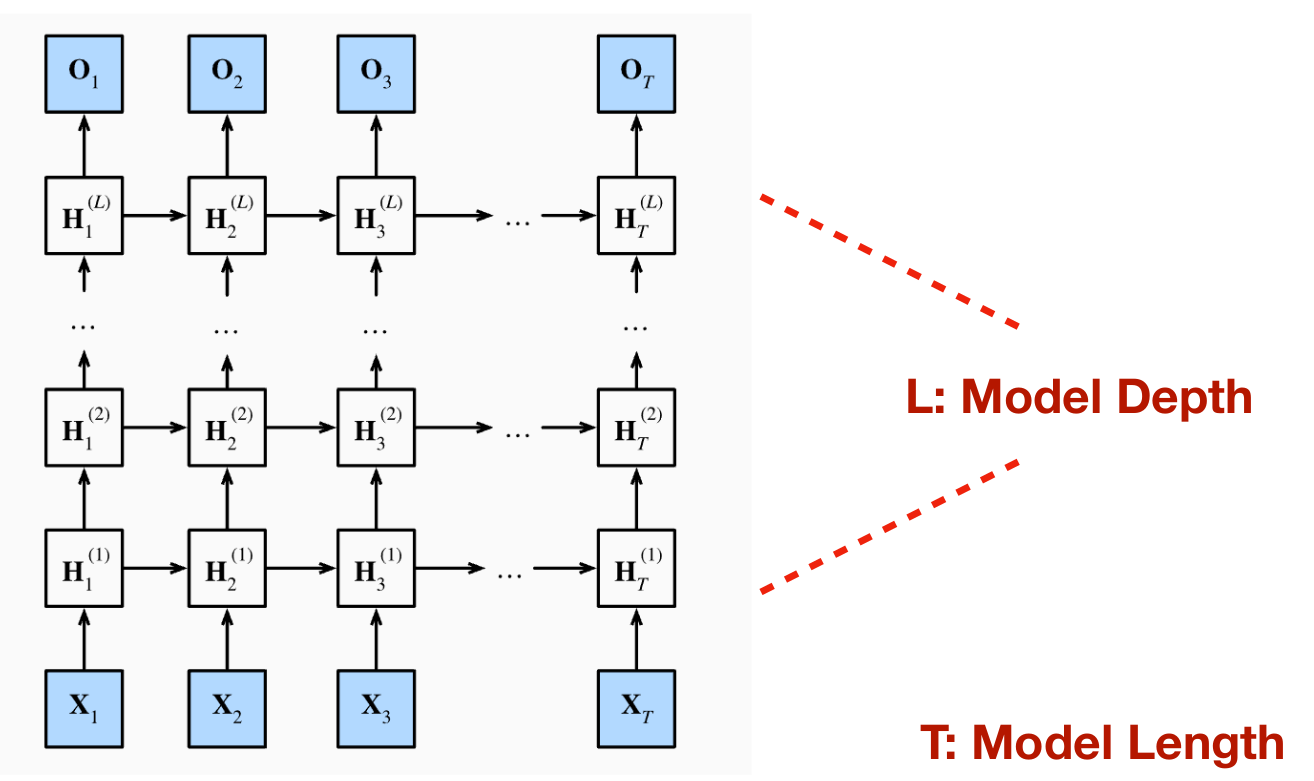
Deep model training with back-propagation algorithm
- Gradient calculated with chain rules
- Some of results calculated in prior layers can be re-used in the following layers, can be back-propagated to save time
What are the issues?
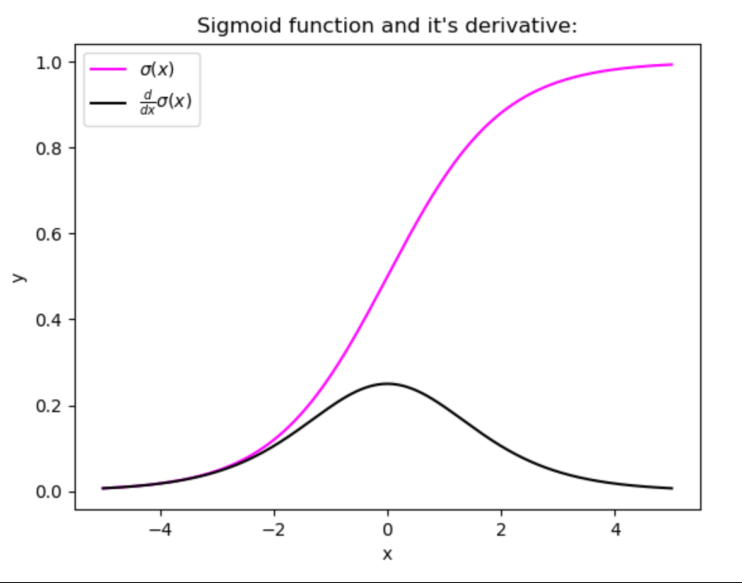
- Observation: For large inputs to sigmoid function, the derivative ‘saturates’ with a derivative very close to zero
- When the backpropagation algorithm chips in, it virtually has no gradients to propagate backward in the network, and whatever little residual gradients exist keeps on diluting as the algorithm progresses down through the top layers. So, this leaves nothing for the lower layers.
Gradient exploding/vanishing is more serious for a recurrent neural network
🧪 -> Refresh the Info
Did you generally find the overall content understandable or compelling or relevant or not, and why, or which aspects of the reading were most novel or challenging for you and which aspects were most familiar or straightforward?)
Did a specific aspect of the reading raise questions for you or relate to other ideas and findings you’ve encountered, or are there other related issues you wish had been covered?)
🔗 -> Links
Resources
- Put useful links here
Connections
- Link all related words