📗 -> 05/14/25: ECS189G-L19
🎤 Vocab
❗ Unit and Larger Context
✒️ -> Scratch Notes
MT Review
- Adam guaranteed faster convergece?
False, not guaranteed - ?
- Full batch shuffling?
False, doesn’t matter for full batch. Could matter for mini batch, but for full batch combined it will be computed in one pass anyway - Discriminator dogs vs other dogs?
No, dogs vs generated dogs - MLP with 1 hidden layer and each 5 layers. Are there 60 params?
Yes - 2(5 * 5 + 5) - Should you use step function between 0 and 1 for Adam optimizer?
No, learning will be less effective because there is zero gradient. - Should you evaluate a rare disease classifier with accuracy?
No, accuracy is biases. Use precision or F1 - Calculate loss function of cross-entropy for random model
- Advantage of CNN vs MLP for images
he just skips lmao. and classify output of >= 0.5 as cats
It will ALWAYS be- Training batch labeling
trivial - CNN model math
- Color image, input 32x32x3, Conv(in=3, out=2, k=5x5, stride=1)
Out: 28x28x2 - How many weights and biases
Params: 5x5x3x2 + 2
Weights: 5x5x3x2
Biases: 2
Skipping to Embeddings?
Training Models:
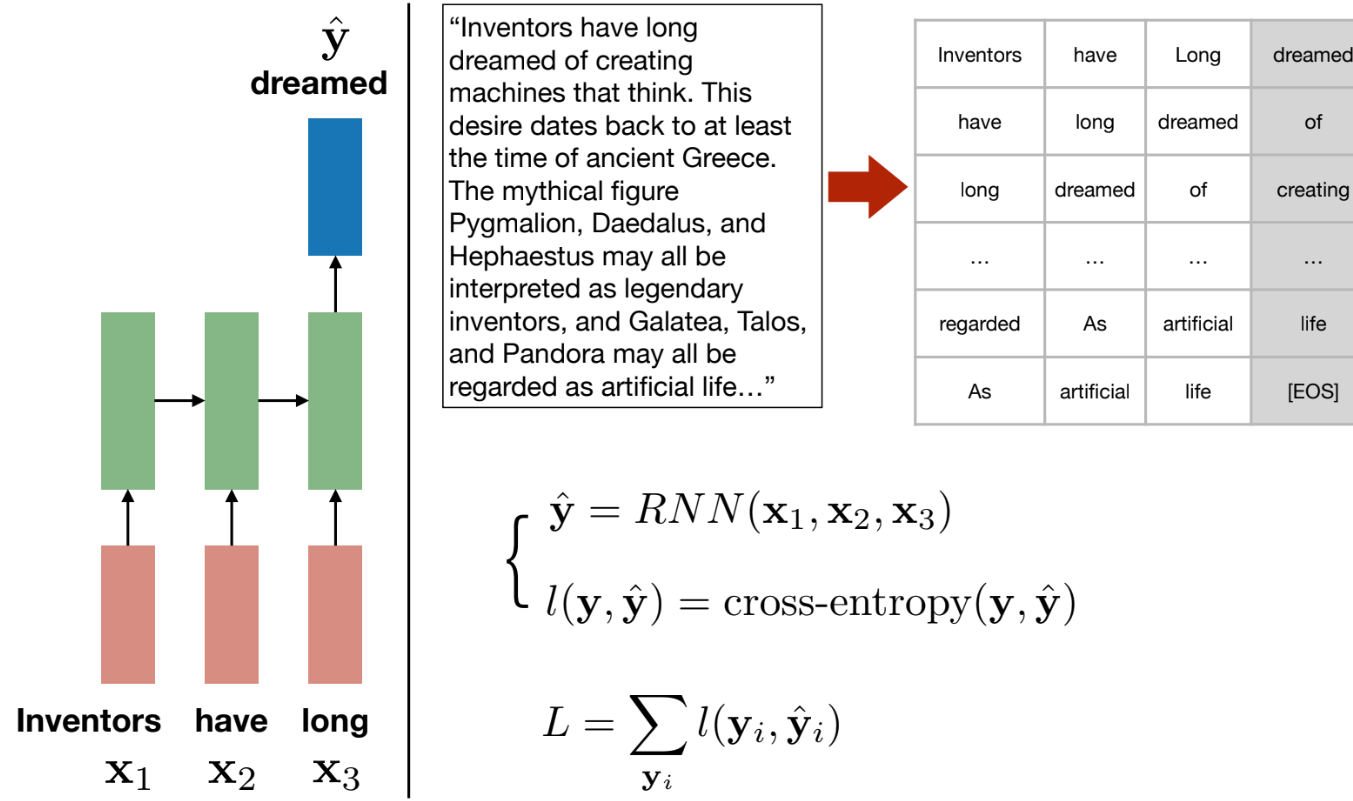
We segment text into input bits (i-3, i-2, i-1) -> and desired output bits (i)
Use cross-entropy loss of generations vs ground truth continuation
Back to RNNS
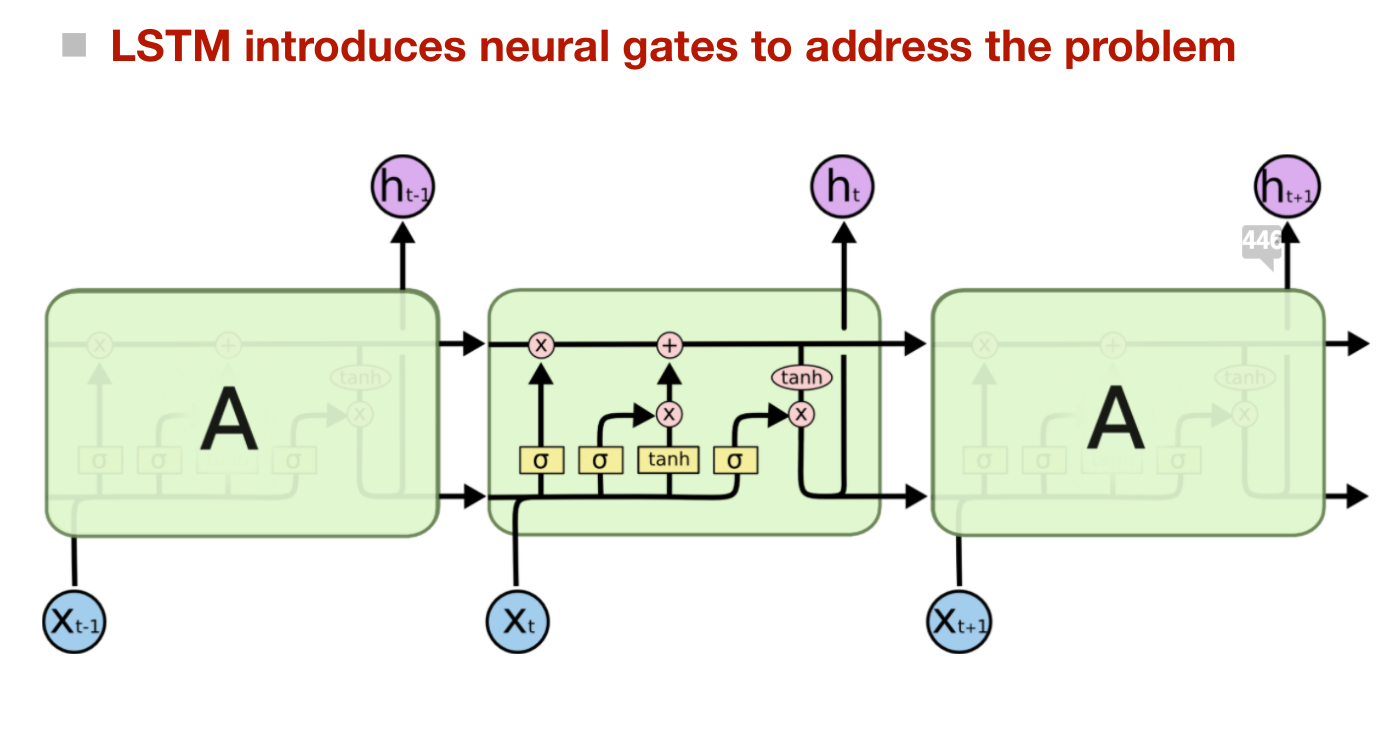
LSTM
Cell State
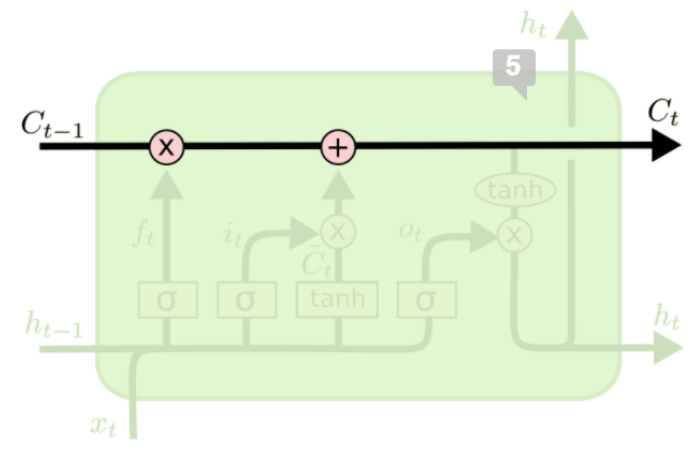
Like a conveyor belt, runs down the change with only minor linear interactions
Allows information flow along it unchanged
Old Cell State Forget Gate
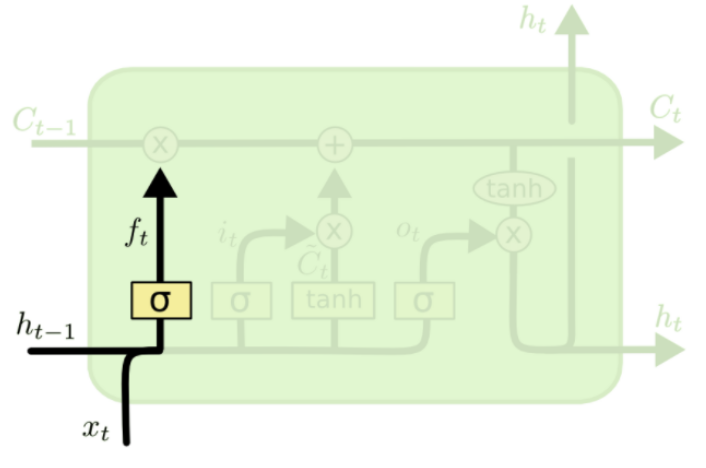
- LSTM needs to decide what info to throw away
- The forget gate defined based on input
and previous step hidden state
New Input Injection Gate
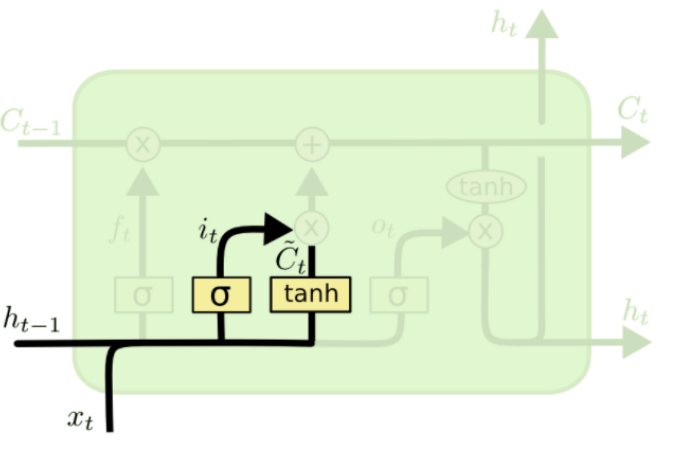
- Needs to inject some new information from the inputs
- Defined based on input
and previous step hidden state
Cell state updating
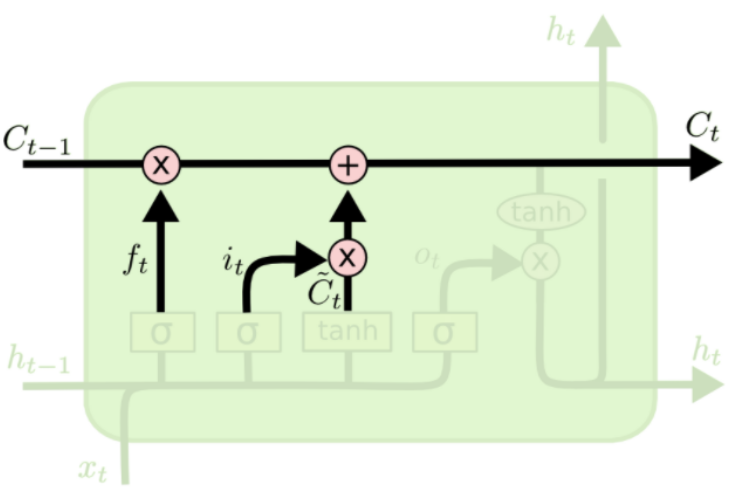
- Element-wise product (not covolution)
- Fuses the old cell state and the newly calculated cell state (based on the inputs)
decides what to forget is a sigmoid, that decides whether to integrate is a pseudo cell state
- Fusion weights decided by the forget state and injection gate
Hidden State
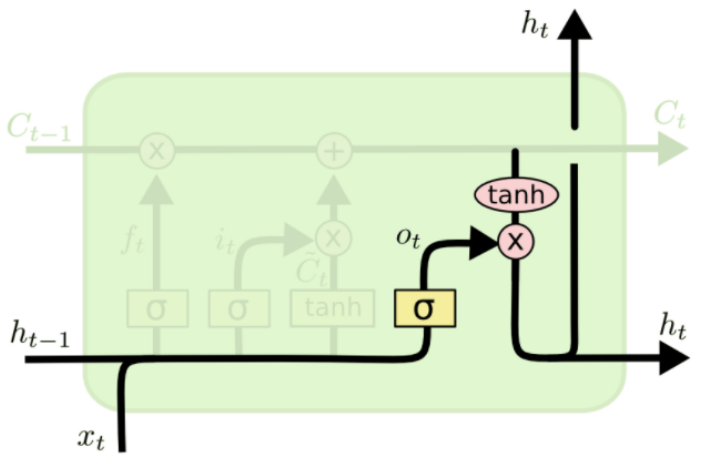
- Final hidden state representation is decided by its new cell state
- But LSTM introduces another neural gate to filter the cell state
- Output gate is decided by the input and previous hidden representation
Motivation
The RNNs are particularly threatened by the gradient exploding/vanishing problem
LSTMs can overcome this
🧪 -> Refresh the Info
Did you generally find the overall content understandable or compelling or relevant or not, and why, or which aspects of the reading were most novel or challenging for you and which aspects were most familiar or straightforward?)
Did a specific aspect of the reading raise questions for you or relate to other ideas and findings you’ve encountered, or are there other related issues you wish had been covered?)
🔗 -> Links
Resources
- Put useful links here
Connections
- Link all related words