📗 -> 05/16/25: ECS189G-L20
🎤 Vocab
❗ Unit and Larger Context
A quick summary of RNNs
Sequence data
- Sequence data examples
- Sequence data representation
Recurrent neural network - Recurrent neural network architectures
- Different RNN structures
Gradient exploding/vanishing problem - What is the gradient exploding/vanishing problem
- Why the problem is more serious for RNN?
LSTM - What is the LSTM internal architecture
- Why LSTM can address the gradient exploding/vanishing problem
- GRU variant model architecture
✒️ -> Scratch Notes
Moving on from RNNs, quick review:
How do LSTMs fix gradient problem?
- LSTMs take out the sigmoid problem where they have a nearly zero gradient at most values
Embeddings:
NLP
Def: NLP is theoretically motivated range of computational techniques for analyzing and representing naturally occurring texts at one or more levels of linguistic analytics.
Attempts through the years:
- 1940s: Weaver’s Memorandum
- 1960s: Grammar Theories
- 1970s: Conceptual Ontologies
- 1980s: Symbolic Models
- 1990s: Statistical Models
Now, with Deep Learning
- 2003: Neural Language Models
- In 2003, Bengio et al. proposed the 1st neural language model.
- 2008: Multi-task learning
- 2013: Word Embeddings
- 2013: NLP Neural Nets
- 2014: Seq-to-seq learning
- 2015: Attention
- 2017: Transformers
- 2018: Pretrained models
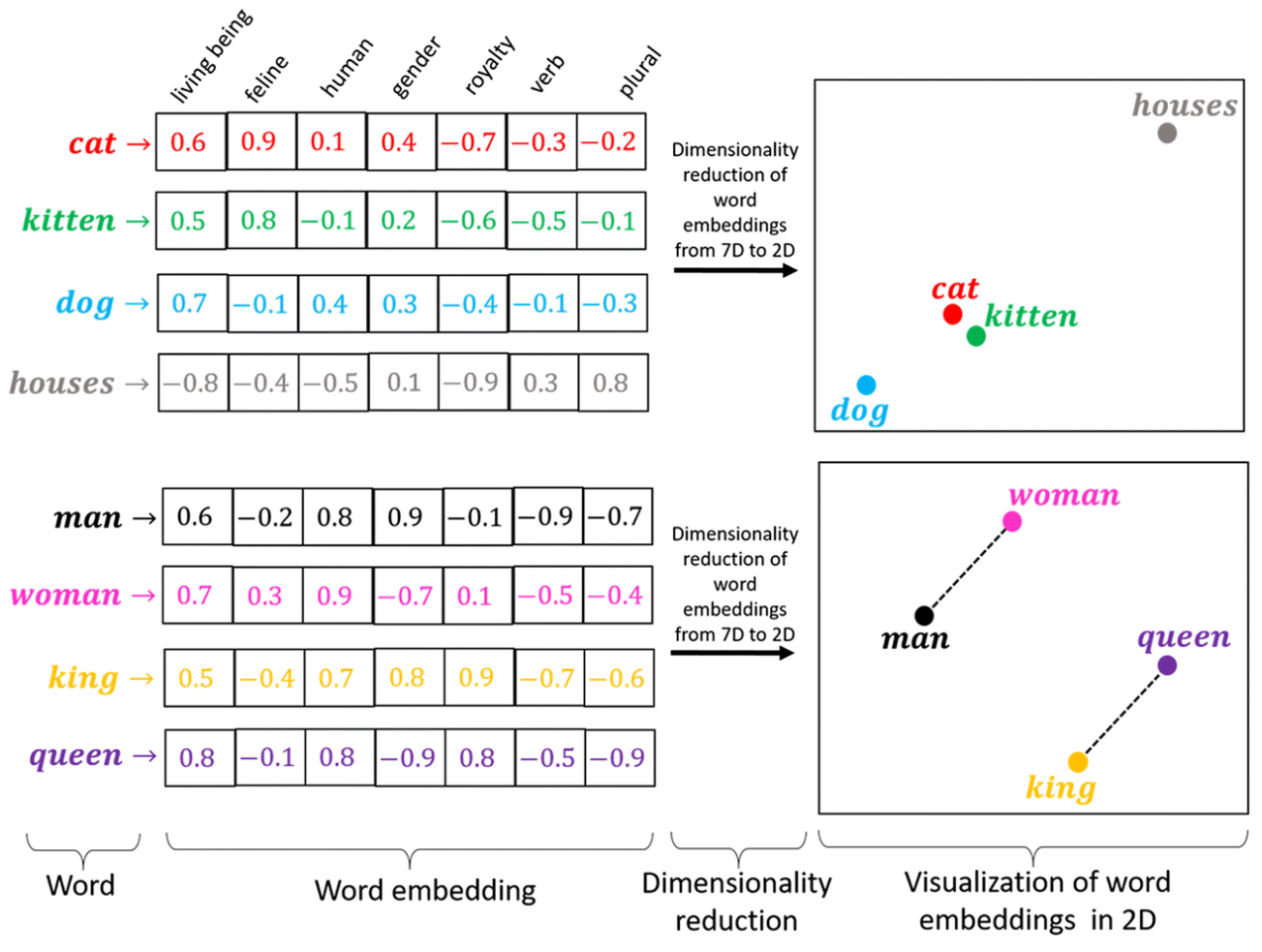
Word Embeddings:
In NLP, word embedding is a term used for the representation of words for text analysis, typically in the form of a real-valued vector that encodes the meaning of the word such that the words that are closer in the vector space are expected to be similar in meaning
Word Prediction with surrounding context:
he curtains open and the stars shining in on the barely
ars and the cold , close stars " . And neither of the w
rough the night with the stars shining so brightly, it
made in the light of the stars . It all boils down , wr
surely under the bright stars , thrilled by ice-white
Notice how some words occur frequently (this is a reduced example):
- Shining
- Light
- dark
- …
Then create a vector representation using surrounding words:
| shining | bright | dark | look | trees | |
|---|---|---|---|---|---|
| stars | 38 | 45 | 27 | 12 | 2 |
- This will make words that are most semantically similar have the closest vectors:
Word 2 ve
CBOW: Predict Current word using surrounding context
MISSING:
Skipgram: Backwards CBOW, predict surrounding context using the current words
CBOW vs Skipgram
Common parts
- Both learn word embeddings based on their surround context
- Both works in an unsupervised manner, requiring no extra supervision information
Differences - CBOW: context->target word; Skipgram: target word->context
- CBOW: several times faster to train than the skip-gram, slightly better accuracy for the frequent words
- skip-gram: works well with small amount of the training data, represents well even rare words or phrases.
🧪 -> Refresh the Info
Did you generally find the overall content understandable or compelling or relevant or not, and why, or which aspects of the reading were most novel or challenging for you and which aspects were most familiar or straightforward?)
Did a specific aspect of the reading raise questions for you or relate to other ideas and findings you’ve encountered, or are there other related issues you wish had been covered?)
🔗 -> Links
Resources
- Put useful links here
Connections
- Link all related words