📗 -> 05/19/25: ECS189G-L21
Embeddings Slides
Transformer Slides
🎤 Vocab
❗ Unit and Larger Context
Continuing embeddings from Bi-directional RNN
Embeddings:
Outline of Embeddings
• Natural Language Processing
• Word2vec and Word Prediction
• Word2vec: CBOW and Skip-gram
• Text Generation with RNN
• RNN Variants: Bi-directional RNN
• RNN Variants: Hierarchical RNN
Summary of Embeddings
Natural language processing history
Word embedding with word2vec
- CBOW: architecture and model training
- Skipgram: architecture and di erence from CBOW
Text generation with Recurrent Neural Network - RNN architecture and training
- Di erent architecture choices
- Bi-directional RNN
- Hierarchical RNN
• What is Attention? To be introduced in next class
Attention and Transformers
- What is Attention?
- Do we really need sequence models?
- Transformer with Attention
- Self Attention
- Multi-Head Self-Attention based Encoder
- A Deep Transformer
- Transfer Learning and BERT with Pre-Training
✒️ -> Scratch Notes
Embeddings
Bidirectional RNN
word2vec and RNN:
- Word2vec captures context patterns
- RNN only captures pattern from forward context
Bidirectional RNN - BRNN - Similar to an RNN, but there is a backward context as well as a forward context:
as well as , where goes in the reverse direction (starts at end) - Both the generation forward and backward
and are combined to create output
Hierarchical RNN
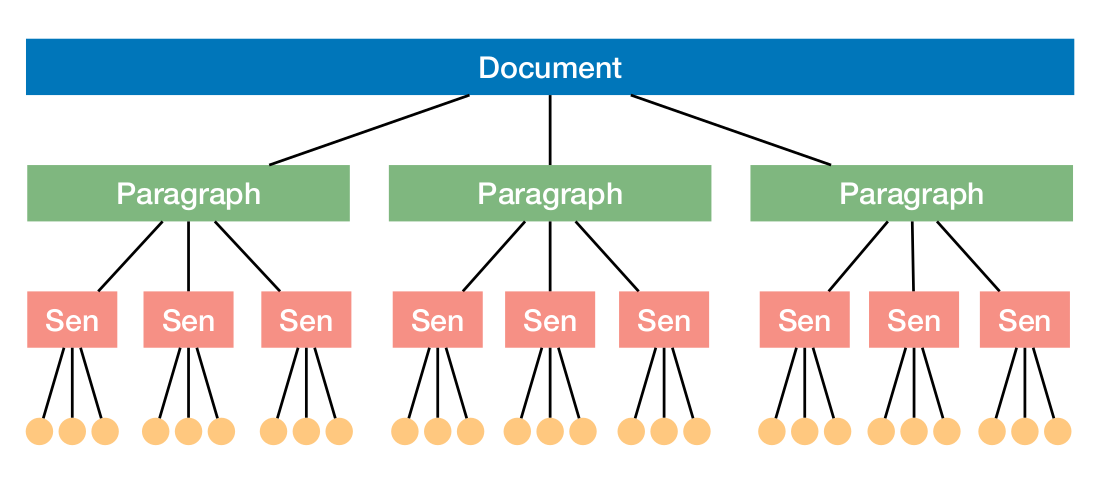
Document hierarchical structure
- Document contains multiple paragraph
- Paragraph contains multiple sentences
- Sentence contains multiple words
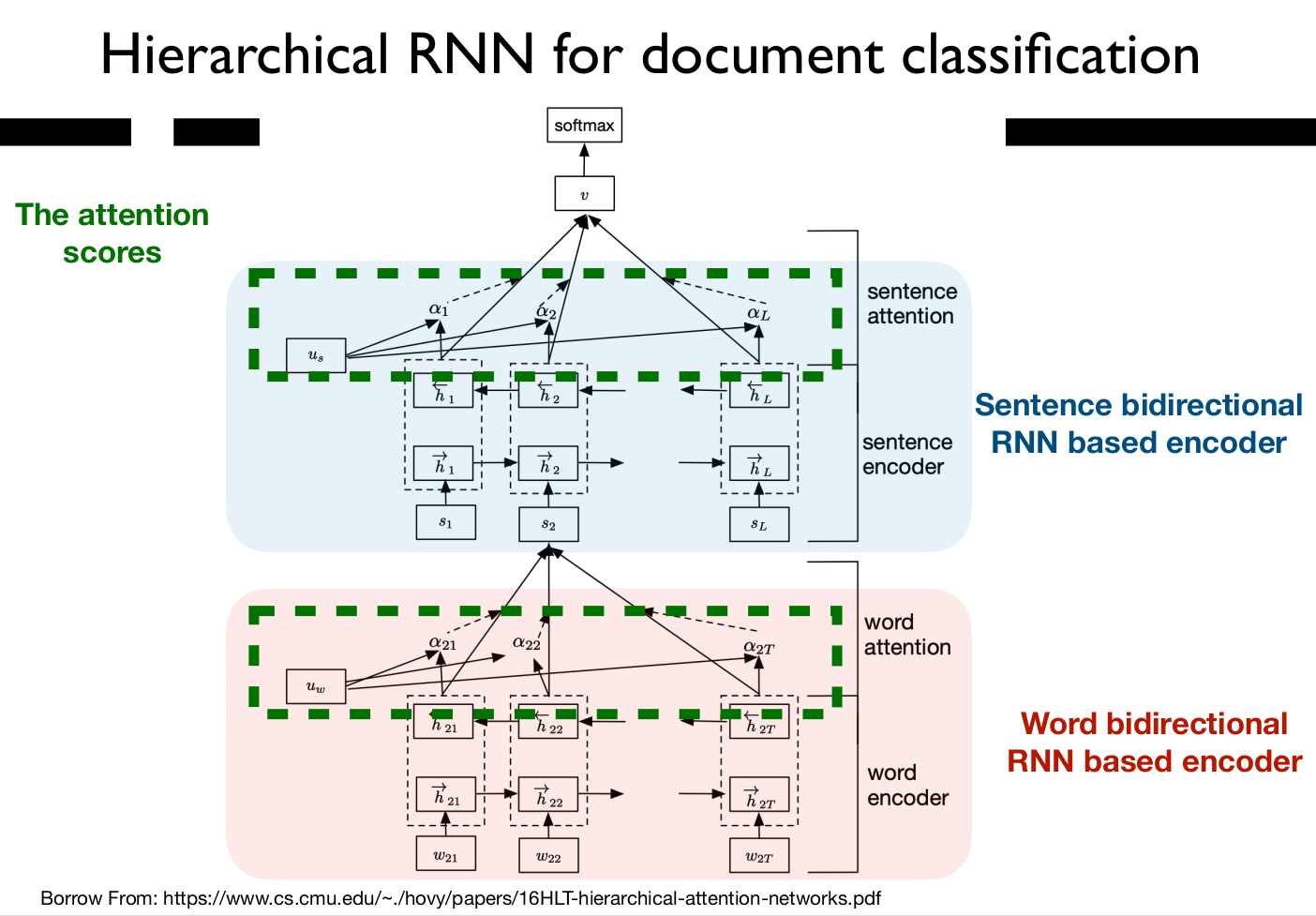
- Learned importance factor. “Word attention” - Could be:
- nn parameter
- Could be:
next slides
Transformer and Language Models
What is Attention?
People selective attend to things:
- Images: Faces of people, and animals
- Text: Names, years, numbers
Not a set thing, people attend to different things (different people etc.)
What is Attention in DL?
One component of a network’s architecture in charg eof managing and quantifying the interdependece between:
- Input and output elements (general attention)
- input elements (self attention)
- different input sources (cross attention)
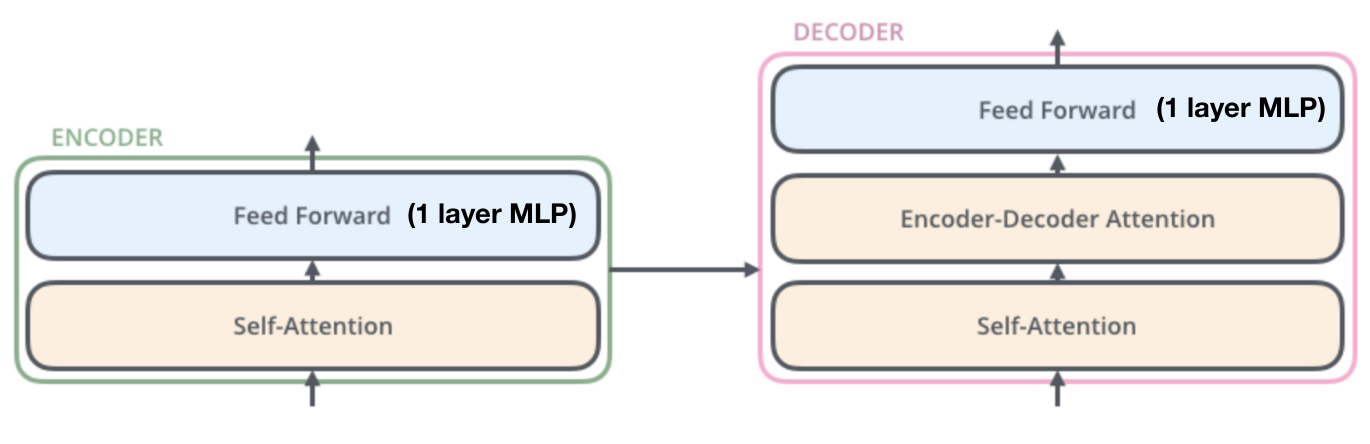
Transformer
Transformer architecture
![]()
- Number of stacked decoders
- FInal decoder projects to subsequent decoders
- Decoders feed into each other, along with encoded input
Encoder / Decoders
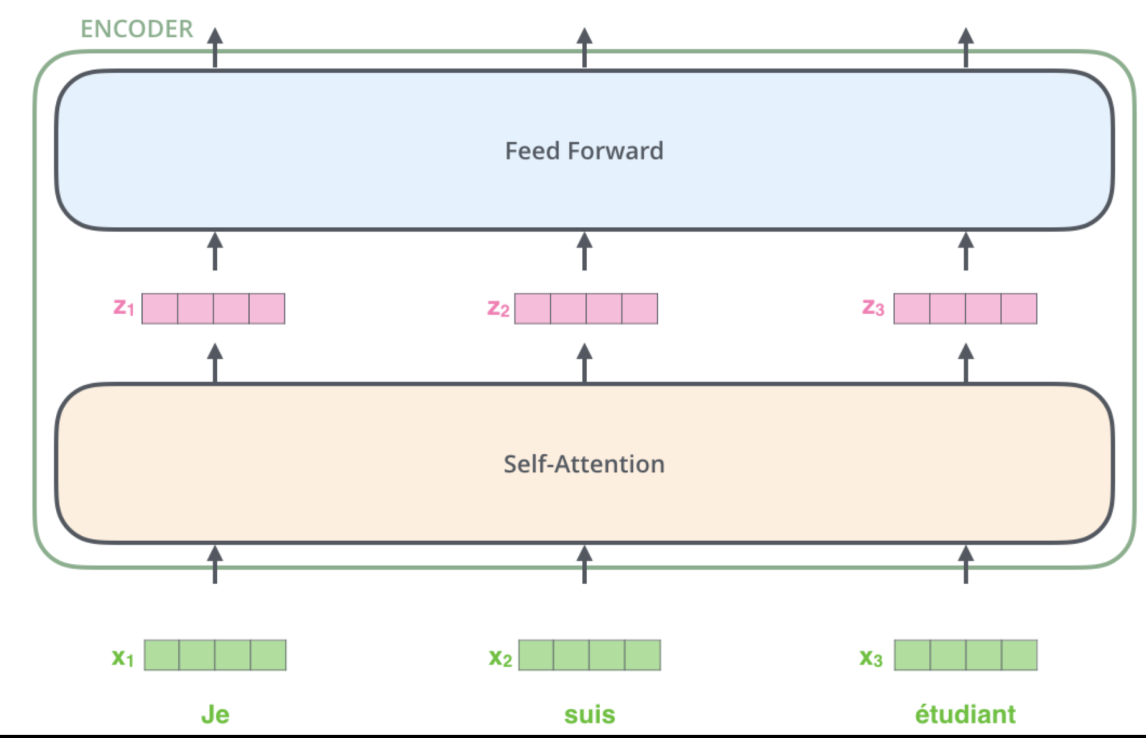
Self Attention:
x - embeddings
q - queries
k - keys
v - values
z - final sum
Now, this is how you calculate the Q, K, V boxes on top left
- z1 is the captured importance from x1 and x2
In the future, we will often hear about Attention Matrix A
REVIEW
🧪 -> Refresh the Info
Did you generally find the overall content understandable or compelling or relevant or not, and why, or which aspects of the reading were most novel or challenging for you and which aspects were most familiar or straightforward?)
Did a specific aspect of the reading raise questions for you or relate to other ideas and findings you’ve encountered, or are there other related issues you wish had been covered?)
🔗 -> Links
Resources
- Put useful links here
Connections
- Link all related words