📗 -> 04/14/25: Deep Learning Optimization
sec_4_stochastic_optimization.pdf - Google Drive
🎤 Vocab
❗ Unit and Larger Context
Small summary
✒️ -> Scratch Notes
DL Model Optimization Key Factors
- Data and Task
- Inputs: Full batch vs instance vs mini-batch
- Outputs: Loss functions
- Model architecture, variables to be learned
- Model variable initialization methods
- Hyper-parameter searching
- Optimizer and optimizer’s hyper-parameters
- SGD vs Momentum vs Adagrad vs Adam vs …
- Optimizer setting hyper-parameters
- Specific algorithm for deep model optimization
- Error backprop algo
Optimizing a Single Variable
Given:
One method: Lagrange
Minimum can be obtained with: Lagrange Multiplier Method
Advantages vs Disadvantages
- Straightforwards and can obtain the precise minimum in theory
- Works for simple functions (convex) with one variable but cannot handle more complex cases (non-convex cases) with multiple variables
- e.g. loss functions for deep learning models
Another Method: Gradient Descent
Start at a random
- Calculate current gradient:
- Update x value (alpha = learning rate):
- Keep updating until convergence gets
Gradient Descent (GD)
GD also works for more complex cases!
Vector of Model Parameters -
Loss Function -
Initialization -
- Calculate the current gradient:
- Update with learning rate:
- Continue until convergence to
Returnas the locally optimal learned model variables
Problems
GD will converge to a local optimum, can’t guarantee global optimum
- Initialization matters:
- Controlled by random seed
Learning Rate:
Large LR can lead to large/drastic updates, leading to divergent behaviors
Small LR requires many updates before reaching the minimum
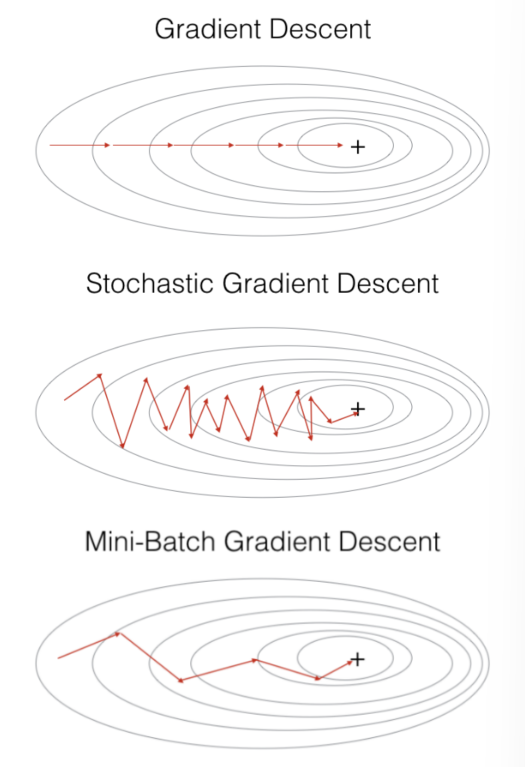
Batch Size
Full Batch GD:
- IE for every instance in dataset, calculate loss, sum them together, and assign that as the Loss
Stochastic GD:
Mini-batch SGD:
Instance-wise SGD: Update the loss function after one data point.
for epoch in range(epochs):
for iteration in batch:
Sum and average them within batch?
Batch Performance analysis:
Full Batch GD:
- Advantage: robust, fast to converge
- Disadvantage: requires large memory, slow in computation
SGD: - Advantage: Fast computation, low memory
- Disadvantage: Not robust, gradient can be slightly mis-leading, can slow down convergence
Mini-batch SGD: - Compromise between Full Batch and SGD
Data ordering can poison gradient updates
Say the data is ordered: 100 dogs, 100 cats, 100 cows, …
If you use batches of 100, you will get VERY biased loss updates
Shuffle Data!
Optimizers
When updating, you can get more fancy (more hyperparameters) than just the learning rate
- Momentum
- Change learning rate
🧪 -> Refresh the Info
Did you generally find the overall content understandable or compelling or relevant or not, and why, or which aspects of the reading were most novel or challenging for you and which aspects were most familiar or straightforward?)
Did a specific aspect of the reading raise questions for you or relate to other ideas and findings you’ve encountered, or are there other related issues you wish had been covered?)
🔗 -> Links
Resources
- Put useful links here
Connections
- Link all related words