📗 -> ECS189G-L8
sec_4_stochastic_optimization.pdf - Google Drive
sec_5_deep_learning_basic
Filling in prior to midterm, did not attend lecture
Summary of Section 4:
Deep Learning model optimization
- Data perspective
- Input: decide to use full batch, instances, mini-batch
- Output (real value, probability, etc.): decide loss function
- Design your model
- Initialize your variables to be learned
- Decide your optimizer
- SGD vs Momentum vs Adagrad vs Adam vs …
- Specify optimizer parameters
- Learning rate
- Other parameters
- Use error back-propagation algorithm (with your GD based optimizer) to learn model variables until convergence
✒️ -> Scratch Notes
Gradient Descent Optimizers
Momentum, Adagrad, Adam
Pure GD:
= Current params / location = Learning Rate = Current Acceleration (not velocity?)
Momentum
Incorporate past gradients into next gradient
- Momentum term weight (usually 0.9)
Adagrad
Learning rate adaptation
- Notice the learning rate is divided by the sqrt sum and epsilon
- Different learning rate for different model variables
- For variables with small gradient, they have larger learning rate
- For variables with large gradient, they have smaller learning rate instead
Adam (Adaptive Moment Estimation)
Incorporates Momentum + Adagrad
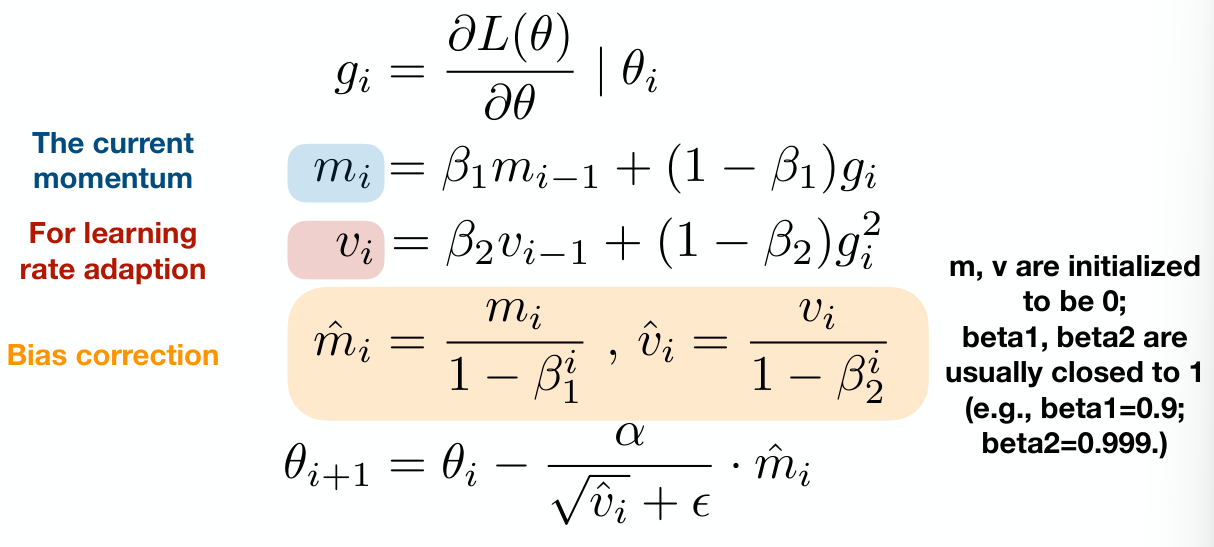
Prediction Output and Loss Functions
Softmax
Notes:
- Basically, scale each output by their proportion of the output, scaled exponential.
- This has the property of turning the full vector output into a probability distribution, summing to 1
- Why
? Related question - It is not particularly important to the ratio, HOWEVER it makes the math easier
has properties that make working with it in derivates/general math much neater. That is why it’s chosen specifically
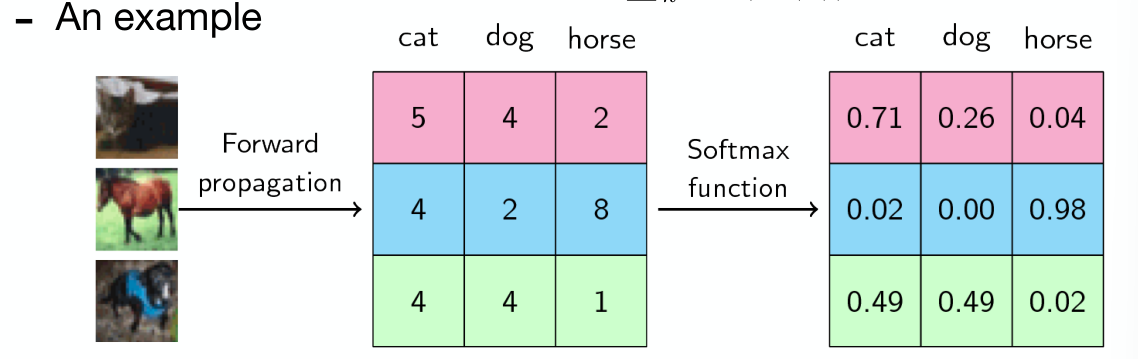
- Notice the distribution scaled to 1
- Notice the exponential scaling
Classification Loss
Mean Absolute Error (MAE) Loss
One hot encode the label, and compare its prediction to truth
Mean Square Error (MSE) Loss
Cross Entropy Loss

More we dont cover as well…
Slides 2
Deep Learning Basics
Why do we need Deep Learning? (DL)
- Great for dealing with complex unstructured data
- He gives the example of discriminating dogs and muffins, they blur the lines of features (number of eyes, nose color, fur color, etc.) needing more complex analysis
What is it?
- He gives the example of discriminating dogs and muffins, they blur the lines of features (number of eyes, nose color, fur color, etc.) needing more complex analysis
- Broad family of ML algos based on Artificial Neural Networks (ANN)
History
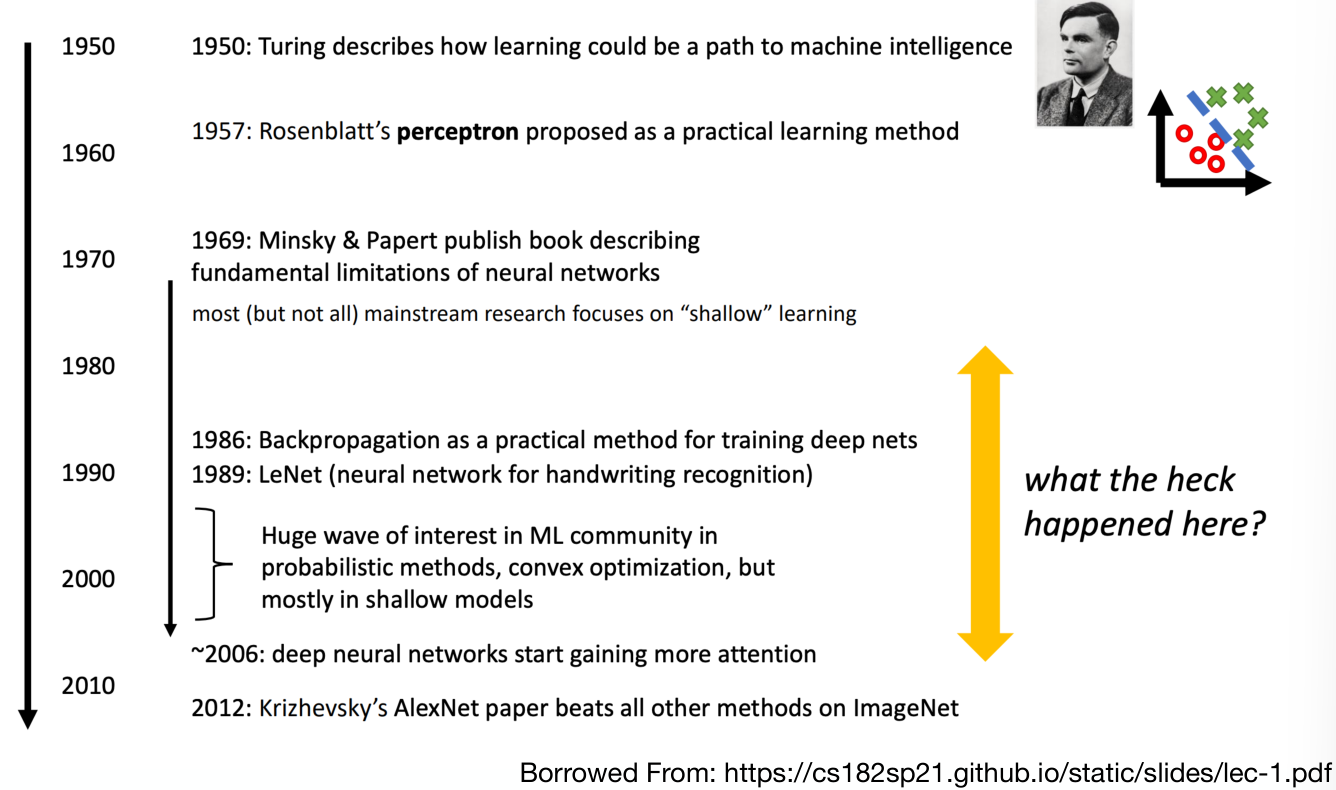
- Brief history of artificial neural networks
Why is it working all of a sudden?
- GPUs, HPCs, Cloud Compute
- Big data
- New deep model architecture
On top of that, they’re increasing exponentially in number of parameters
🧪 -> Refresh the Info
Did you generally find the overall content understandable or compelling or relevant or not, and why, or which aspects of the reading were most novel or challenging for you and which aspects were most familiar or straightforward?)
Did a specific aspect of the reading raise questions for you or relate to other ideas and findings you’ve encountered, or are there other related issues you wish had been covered?)
🔗 -> Links
Resources
- Put useful links here
Connections
- Link all related words