P1
a) (5 pts) What is the criteria to choose a suitable q? Explain why it is important to choose suitable q in terms of the time complexity of computing the hash value for P and substrings of T. Generalize your answer for any alphabet size and length of P.
q is selected such that d mod q fits within 1 computer word. If it were chosen otherwise, certain constant time operations in the algorithm would become O(n), as BigInt arithmetic would need to be involved. These operations include calculating the rolling hash and comparing the hashes.
b) (2 pts) What is the definition of a spurious hit?
A hit is a match for the hash value of a pattern and a hash value of the text.
A spurious hit is when the hash matches are not actually identical, like for example:
- P=01, T=11. When q=10 and the values get %10, they will both have a hash of 1, but not be identical.
c) (3 pts) Primitive operation means character-by-character matching between pattern P and a substring of T. Explain when this operation takes place in this algorithm.
This operation is used when a hit is detected. The character-by-character matching is required to distinguish a spurious hit from a true match.
d) (5 pts) How does pre-computing
where m indicates the length of pattern P and d indicates the alphabet size, help improving the time complexity of the algorithm? Please explain your answer mathematically by discussing the performance of the algorithm wrt h.
Normally, calculating
e) (5 pts) Provide an example where the rolling hash technique is used to compute the hash values of substrings of an input string T. You can pick any suitable String T and pattern P where the alphabet includes the extended ASCII character set.
Since we are using the extended ASCII character set:
- d=256, T=“Substring”, P=“str”, m=3
- Hashes calculated by:
- For first m iterations:
hash = hash * d + ord(S[i]) - Afterwards:
hash = (hash * d) - (ord(S[i]) * h * d) + ord(T[i+m])- Effectively, this shaves off the ith digit of the text from the hash and adds in the i+m digit.
- For first m iterations:
Since no q was specified, computation will be done with no modulo.
Pattern:
- ‘str’=7566450
Text: - ‘Sub’=5469538 : No match
- ‘ubs’=7692915 : No match
- ‘bst’=6452084 : No match
- ‘str’=7566450 : Match
- ‘tri’=7631465 : No match
- ‘rin’=7498094 : No match
- ‘ing’=6909543 : No match
Note how large the values get because of the alphabet size, even with a pattern of only size 3.
f) (4 pts) In the worst case, what is the number of spurious hits in this algorithm?Explain why.
The worst case would be the entire text becoming a spurious hit when hashed, for example:
- P=01, T=11111111. If q=10, the entire text will become a hash match, despite there not being a true match in the whole text.
P2
Analyze the time complexity of Advanced Z-Algorithm. Provide the breakdown of the time complexity and explain how it is calculated. Make all the necessary assumptions about the length of the input string, pattern, so forth.
Copying the pseudo code from the slides:
def Z_arr_calc(String I):
int Z[I.length]
left = 0
right= 0
for k=1 to I.length do
if k > right then # outside of Z-box
left = right = k
while right < I.length and I[right] == I[right-left] do
right++
Z[k] = right-left
right-=1
else # inside of Z-box
k1 = k-left
if Z[k1]+k < right + 1 then
Z[k] = Z[k1]
else
left = k
while right < I.length and I[right] == I[right-left] do
right ++
Z[k] = right-left
right-=1
return ZBy inspection, we can see that the dominating term in the algorithm will be the k iterators: for k=1 to I.length. This is an
Inside we see smaller while loops like the right++ while loop, but these are not repeated, as they get reused by the # inside of z-box else statements. These loops are at most
P3
We are using the Z-Algorithm algorithm given String T, Pattern P, and divider character ‘$’. Let’s assume that S = P+’$’+T. For computing the Z-array (0-index), 1≤ k≤|S| . If k is inside the Z-box, we use the pre-computed Z-values, and if k is outside of the Z-box, we use the naive approach to compute the Z-values. Assume that the input string S is unknown. If Z[20] =7, and Z[4]=2, Z[1]=1, what is Z[21]? Provide your explanation and strategy.
Assuming that Z is 0 indexed, Z[21] would be 1. This is because Z[20] guarantees that the characters after it match the first 7 characters of the pattern, meaning Z[0-6] == Z[20-26]. Z[21] is included in this, and will have its z-score reused from Z[1] which is 1. Note that Z[21] is small enough to be included completely in the z-box.
P4
Construct a suffix tree for the string “abcabdacd$”.
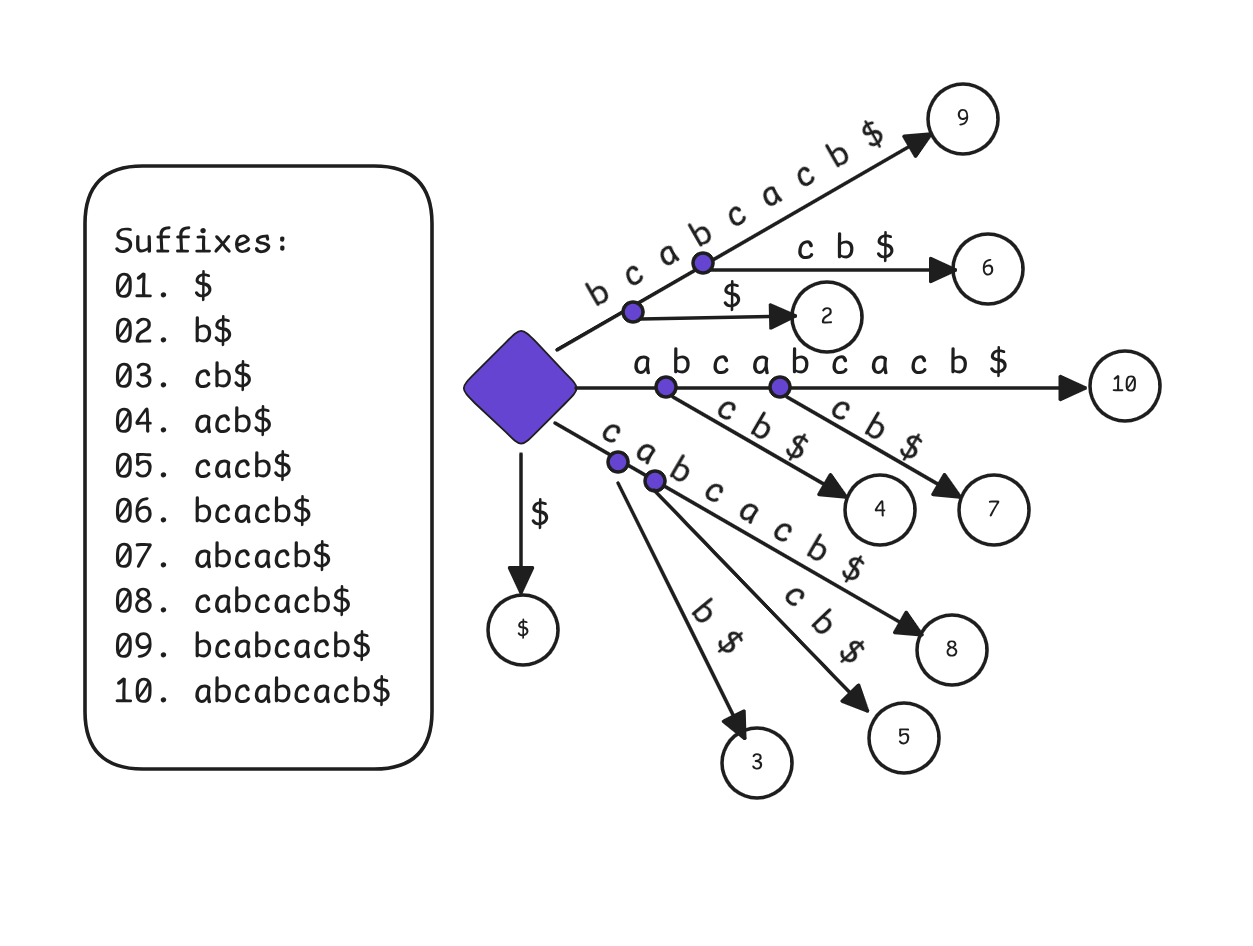
P5
Suppose you have the linear string matching Z-Algorithm that takes strings S and T and determines if S is a substring of T. However, you want to use it in the situation where S is a linear string but T is a circular string (a circular string has no beginning or ending position). You could break T at each character and solve the linear matching problem |T| times, but that would be very inefficient. Show how to solve this problem by only one use of the string matching algorithm. Only explain your strategy and support your solution with an example.
My strategy would solve it in
I would redefine the pattern used in the Z algorithm from
With the example: P=“loop”, T=“oplopolo”, the Z-Algorithm will match on the text: I=“loop$olooplopolo”.
After running, we correctly find the match in T when it acts as a circular string.

P6
a) (10 pts) Given string T = “y a b b a d a b b a d p $”, provide an algorithm pseudocode to construct a suffix tree for T. Show how the tree is constructed using your algorithm step by step.
This algorithm is inefficient for space and time, but correctly constructs the suffix tree / trie.
def char_to_index(char X):
// some logic, like ord(char) - ord('a')
return index; // number between [0, Q+1]
def suffix_constructor(string T, int vocab_size):
// create root of trie
// size of vocab plus one for terminator
root = [NULL] * (vocab_size+1);
I = T + '$'
for int i in len(I):
suffix = I[i:];
curNode = root;
for char ch in suffix:
if ch == '$':
curNode[vocab_size] = true;
continue;
// else
index = char_to_index(ch)
if curNode[index] != NULL:
curNode = curNode[index];
else:
newNode = [NULL] * (vocab_size+1);
curNode[index] = newNode;
curNode = newNode
return rootb) (10 pts) Next, provide a pseudocode for a pattern matching algorithm that takes the constructed suffix tree and pattern P as input to search for a pattern P (e.g., P = “bad”). Assuming that we have a finite alphabet, analyze the time complexity of your algorithm. Provide details to justify your analysis.
def char_to_index(char X):
// some logic, like ord(char) - ord('a')
return index; // number between [0, Q+1]
def search_suffix_tree(string P, SuffixTree root, int vocab_size):
curNode = root // O(1)
for char ch in P: // O(N)
index = char_to_index(ch) // O(1)
if curNode[index] != NULL: // O(1)
curNode = curNode[index] // O(1)
continue // O(1)
// needs to match every character
return false // O(1)
// at this point, we have successfully found our match
return true; // O(1)Assuming a finite alphabet, our algorithm runs in
- We have a loop that iterates through every character in the pattern, which makes the algorithm at least
- Inside the loop, we only perform
operations, like array lookups and variable assignments.
In order to find p=‘bad’ in our suffix tree, and representing the suffix tree as a hashmap at each step instead:
- We check for ‘b’ in our root hash.
root = [ a: node, b: node, d: node, y: node, $: true]. We find it, and we update our current node to the one pointed to by ‘b’. - We check for ‘a’ in our current nodes hash.
cur = [a: node, b: node]. We find ‘a’, and we update cur. - We check for ‘d’ in our current node.
cur = [d: node]. We find it, and we know that the substring “bad” is present in our text.
P7
a) (8 pts) Write the algorithm pseudocode to construct a suffix array given a string S. What is the time complexity of your algorithm? Explain.
Naive: Attempt one
Assuming c-string behaviors, we can build a suffix array in
def string_to_suff_arr(char *S):
S_copy = S + "$"
n = strlen(S_copy)
char *suff_arr[n+1]
for i in range(n): //
// add a byte offset to 'remove' some of the front in O(1)
suff_arr[i] = S_copy + i
sort(suff_arr) // O(nlogn * n)
return suff_arrOptimized: Attempt two
The simplest
- Build a suffix tree (using Ukkonen’s algorithm is
) - Traversing it in lexicographical order with DFS (which is also
).
Building strings was left unoptimized in pseudocode, but would need to be optimized in order to not increase computational complexity. Call should be substituted for a StringBuilder object but omitted for clarity.
def string_to_suff_tree(string S):
// Ukkonen's algorithm
return suff_tree
def dfsRec(node, current, arr):
// current is the string representation of path
if '$' in node:
arr.push(current + '$')
// or if index wanted and assuming nodes stored index
// arr.push(node['$'].val)
// assume that suff tree has a iterator for visiting lexicographically
// would be trivial to code, sort for finite dict is O(1)
while (char ch = node.lex_iterator()):
next = node[ch]
dfsRec(next, current+"ch", arr)
return
def string_to_suff_arr(string S):
// O(n) if using Ukkonen's algorithm
root = string_to_suff_tree(S)
suff_arr[len(s)+1]
// Exploring a suffix tree using DFS is O(n),
// because it has at most O(n) edges/nodes
dfsRec(root, "", suff_arr)
return suff_arr b) (8 pts) Write the algorithm pseudocode which takes a suffix array as input and constructs the LCP array corresponding to the input suffix array.
def common_prefix(s1, s2):
i = 0
# O(n)
while i < len(s1) and i < len(s2):
if s1[i] != s2[i]:
return i
i++
return i
def suff_array_to_LCP(string S, int[] suff_arr):
LCP = [0]*n
# O(n)
for i in range(1, len(suff_arr)): # i=0 is 0
# shorthand for getting strings from the indices
s1 = S[suff_arr[i]:]
s2 = S[suff_arr[i-1]:]
LCP[i] = common_prefix(S, s1, s2)
return LCP
Naive implementation is
Advanced algorithms like Kasai’s algorithm can perform the construction of the LCP array from the suffix array in
c) (8 pts) Write the algorithm pseudocode to construct a suffix tree given a suffix array and its corresponding LCP array as inputs.
Class Node:
# implementation for suffix tree node
# ignoring implementation of children, depth
def build_suff_tree(string S, int[] suff_arr, int[], LCP):
n = len(suff_arr)
root = Node(0)
stack = [root] # stack tracks current path from root
for i in range(n):
curr_lcp = LCP[i] if i > 0 else 0
prev = None
# pop stack until we find a node at the right depth
while len(stack) > 1 and stack[-1].depth > curr_lcp:
prev = stack.pop()
# create internal node if needed
if stack[-1].depth < curr_lcp:
internal = Node(curr_lcp)
internal.children[S[prev.start + curr_lcp]] = prev
stack[-1].children[S[suff_arr[i]]] = internal
stack.append(internal)
# always create and attach a leaf
leaf = Node(n - suff_arr[i])
leaf.start = suff_arr[i]
stack[-1].children[S[suff_arr[i] + curr_lcp]] = leaf
stack.append(leaf)
return root