Problem 1 (5 points)
Provide an example for finding multiple occurrences of a pattern P in an input string S using the binary search method on suffix array of S. Show your work through execution of the algorithm and provide your assumptions.
The suffix array gives us the indexes of the sorted suffix strings. Due to the substrings being sorted, we can use binary search to find the position of pattern P within S.
As an example, we will perform binary search on the following:
- S=“banana”, P=“ana”
This consists of the following steps:
- First, we build the suffix array .
- Then, we perform binary search on it, comparing our pattern P against the suffix represented by the suffix array at index i. We iterate through the suffix array until we eliminate the entire array, or find all occurrences of P.
This algorithm has a complexity of
Part 1 - Building suffix array
First we find all substrings.
| Index | Suffix |
|---|---|
| 0 | banana$ |
| 1 | anana$ |
| 2 | nana$ |
| 3 | ana$ |
| 4 | na$ |
| 5 | a$ |
| 6 | $ |
Then we sort lexicographically to get the following suffix array:
- SA=[6,5,3,1,0,2,4]
| SA Index | Substring index | Suffix |
|---|---|---|
| 0 | 6 | $ |
| 1 | 5 | a$ |
| 2 | 3 | ana$ |
| 3 | 1 | anana$ |
| 4 | 0 | banana$ |
| 5 | 2 | nana$ |
| 6 | 4 | na$ |
Part 2 - Binary Search
Iteration 1
low, high = 0, n-1
mid = (low+high) // 2 (=3)
SA[3] = 1, S[1:] = “anana$”
Following our O(m) comparison, we find our first match.
Iteration 2
Usually we would update our low/high following an iteration of binary search, but since we already found a match we just check above and below our current index to find all possible matches. (while (mid+i) match; while (mid-i) match; in very rough pseudocode)
We first check SA[mid+1]=0, S[0:] = “banana$”
- No match
Iteration 3
SA[mid-1]=3, S[3:]=“ana$”
- Match
Iteration 4
SA[mid-2]=5, S[5:]=“a$”
- No match
Completed
We return our matches at indexes 3 and 5.
Problem 2 (20 points)
(10 points) Given a text T = “never—ever—say—never—again”, create BWT(T$) and show your complete work. Explain the approach you used to create BWT(T).
(10 points) Reverse BWT(T$) and show your complete work. Show all the steps and explain your approach.
Part a)
I created BWT(T$) using the naive approach with python:
T = "never--ever--say--never--again"
Tp = T + "$"
n = len(Tp)
# creating all rotations
circ_shifts = []
for i in range(n):
circ_start = Tp[n-i:]
rot = circ_start+Tp[0:n-i]
circ_shifts.append(rot)
print(f"{i}: {rot}")
# sorting
sorted_shifts = sorted(circ_shifts)
for i, rot in enumerate(sorted_shifts):
print(f"{i}: {rot}")
# extracting last col
BWT_Tp = ""
for rot in sorted_shifts:
BWT_Tp += rot[-1]
print(BWT_Tp)All rotations:
0: never--ever--say--never--again$
1: $never--ever--say--never--again
2: n$never--ever--say--never--agai
3: in$never--ever--say--never--aga
4: ain$never--ever--say--never--ag
5: gain$never--ever--say--never--a
6: again$never--ever--say--never--
7: -again$never--ever--say--never-
8: --again$never--ever--say--never
9: r--again$never--ever--say--neve
10: er--again$never--ever--say--nev
11: ver--again$never--ever--say--ne
12: ever--again$never--ever--say--n
13: never--again$never--ever--say--
14: -never--again$never--ever--say-
15: --never--again$never--ever--say
16: y--never--again$never--ever--sa
17: ay--never--again$never--ever--s
18: say--never--again$never--ever--
19: -say--never--again$never--ever-
20: --say--never--again$never--ever
21: r--say--never--again$never--eve
22: er--say--never--again$never--ev
23: ver--say--never--again$never--e
24: ever--say--never--again$never--
25: -ever--say--never--again$never-
26: --ever--say--never--again$never
27: r--ever--say--never--again$neve
28: er--ever--say--never--again$nev
29: ver--ever--say--never--again$ne
30: ever--ever--say--never--again$n
Sorted (sorting rule:
0: $never--ever--say--never--again
1: --again$never--ever--say--never
2: --ever--say--never--again$never
3: --never--again$never--ever--say
4: --say--never--again$never--ever
5: -again$never--ever--say--never-
6: -ever--say--never--again$never-
7: -never--again$never--ever--say-
8: -say--never--again$never--ever-
9: again$never--ever--say--never--
10: ain$never--ever--say--never--ag
11: ay--never--again$never--ever--s
12: er--again$never--ever--say--nev
13: er--ever--say--never--again$nev
14: er--say--never--again$never--ev
15: ever--again$never--ever--say--n
16: ever--ever--say--never--again$n
17: ever--say--never--again$never--
18: gain$never--ever--say--never--a
19: in$never--ever--say--never--aga
20: n$never--ever--say--never--agai
21: never--again$never--ever--say--
22: never--ever--say--never--again$
23: r--again$never--ever--say--neve
24: r--ever--say--never--again$neve
25: r--say--never--again$never--eve
26: say--never--again$never--ever--
27: ver--again$never--ever--say--ne
28: ver--ever--say--never--again$ne
29: ver--say--never--again$never--e
30: y--never--again$never--ever--sa
Extracting the last column: BWT(T'): nrryr-----gsvvvnn-aai-$eee-eeea
The BWT string is successfully generated.
Part b)
I reversed the string by first building the rank array, and then following the linked list to build the reversed string, before reversing the string to get T’ back.
# creating the rank array
rank = [0 for _ in range(n)]
chars_used = sorted(list(set(BWT_Tp)))
counter = 0
for ch_target in chars_used:
for i, ch_inner in enumerate(BWT_Tp):
if ch_target == ch_inner:
rank[i] = counter
counter += 1
print(rank)Rank array (0-indexed): [20, 23, 24, 30, 25, 1, 2, 3, 4, 5, 18, 26, 27, 28, 29, 21, 22, 6, 9, 10, 19, 7, 0, 12, 13, 14, 8, 15, 16, 17, 11]
# building the reversed string
cur_index = BWT_Tp.index('$')
reverse_Tp = ""
for _ in range(n):
reverse_Tp += BWT_Tp[cur_index]
cur_index = rank[cur_index]
print(reverse_Tp)
print(reverse_Tp[::-1])Prints:
$niaga--reven--yas--reve--revennever--ever--say--never--again$
The original string is successfully recovered from the BWT string.
Problem 3 (5 points)
What is the Brute force (i.e., naïve) running time for creating BWT string? Explain.
Using my naive code above as a model:
def naive_BWT(T):
Tp = T + "$"
n = len(Tp)
# creating all rotations
circ_shifts = []
for i in range(n): # O(n)
circ_start = Tp[n-i:]
rot = circ_start+Tp[0:n-i] # O(n)
circ_shifts.append(rot)
# sorting
sorted_shifts = sorted(circ_shifts) # O(n * nlogn)
# extracting last col
BWT_Tp = ""
for rot in sorted_shifts: # O(n)
BWT_Tp += rot[-1]
return BWT_Tp- Creating shifts of circular strings: O(n * n)
- Sorting rotations of T: O(n * nlogn). Its O(nlogn) time to sort, and each comparison is O(n)
- Extracting last column: O(n * 1)
Total:
Which reduces to:
Problem 4 (20 points)
Provide the pseudocode for reversing a BWT string. Analyze the time complexity of your algorithm.
Given a BWT string, the following code reverses it.
- It builds the rank array
- It follows the pointers to build the reverse string
- Reverses it to recover the original string
BWT_Tp = # ... define the BWT
# creating the rank array
rank = [0 for _ in range(n)]
chars_used = sorted(list(set(BWT_Tp)))
counter = 0
for ch_target in chars_used: # O(dict)
for i, ch_inner in enumerate(BWT_Tp): # O(n)
if ch_target == ch_inner:
rank[i] = counter
counter += 1
# building the reversed string
cur_index = BWT_Tp.index('$')
reverse_Tp = ""
for _ in range(n): # O(n)
reverse_Tp += BWT_Tp[cur_index]
cur_index = rank[cur_index]
Tp = reverse_Tp[::-1] Putting aside the complexity analysis of building strings and assuming it can be handled efficiently:
- Creating the rank array (with dictionary
) is done in . While this could be optimized for performance, the big-O performance remains since will reduce to a constant - Building the reverse string is done in
. Rank array indexes are found in constant time, and iterated through times. - Reversing the string could be done in constant time but does not affect final complexity whether or not its optimized.
Final complexity:
Problem 5 (20 points)
Discuss and fully explain the overall time complexity of Ukkonen’s algorithm when:
a. (8 points) No tricks are used.
b. (6 points) Suffix links and skip/count trick are used.
c. (6 points)Suffix links, skip/count trick are used in conjunction with Edge label compression trick.
a) With no tricks, the algorithm is
- There are n phases to the algorithm
- In each iteration i, the algorithm must extend the suffix tree of
by updating each suffix with the current character. - Within each extension, the algorithm has the potential to trace the entirety of the current prefix’s path (a length of n).
This leads to a worst case complexity of.
b) With suffix links and the skip/count trick, the complexity is reduced to
- There are till n phases to the algorithm.
- Suffix links and the skip/count trick help the algorithm to traverse the tree’s nodes quickly, and improves the runtime for reaching leaves to O(1) instead of O(n).
- However, the algorithm still has to make n extensions at each step for each leaf.
The leads to time complexity of
c) With suffix links, the skip/count trick, and the edge label compression trick the complexity is reduced to O(n).
- There are still n phases to the algorithm
- Now when the end is incremented, all values are updated in constant time than O(n) time as the global end pointer is updated. This comes as a result of edges being represented as pairs of characters (
[start, end]) rather than the full string. This both reduces the space complexity, and computational cost of extending leaves.
Total:
Problem 6 (10 points)
Which suffix tree construction algorithm has online property? Explain with an example.
Ukkonen’s algorithm is the suffix tree construction algorithm with the online property.
The online property is the characteristic that during each stage i of the n stages of Ukknonen’s algorithm the tree created for the prefix
For example, when constructing the suffix tree for T=“GRANDMOTHER”, the suffix tree created for the substring “GRAND” following stage i=5 will be a valid suffix tree, representing suffixes S=[“GRAND”, “RAND”, “AND”, “ND”, “D”].
Problem 7 (20 points)
Describe how Ukkonen Algorithm constructs a suffix tree for an input string S[1:n]. Use the notions of prefix and suffix in your explanation. For every extension rule, provide a visual example.
Ukkonen’s Algorithm constructs a suffix tree for an input string
- If the path for the suffix
ends at a leaf, then the tree is updated with character at the end of the leaf edge. This is done in O(1) time for many leaves in the tree simultaneously through a global end pointer that is updated as the algorithm iterates through each stage.
| Before | After |
|---|---|
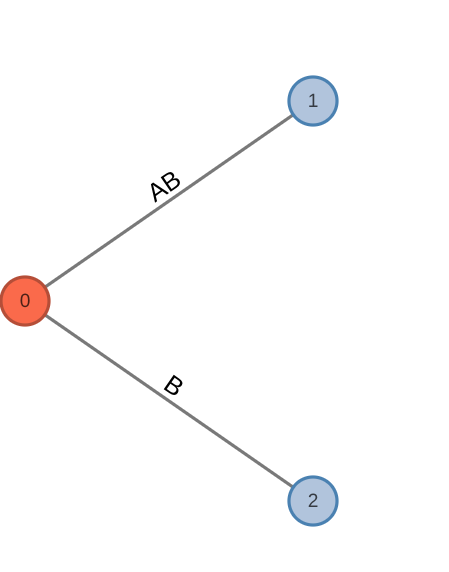 | 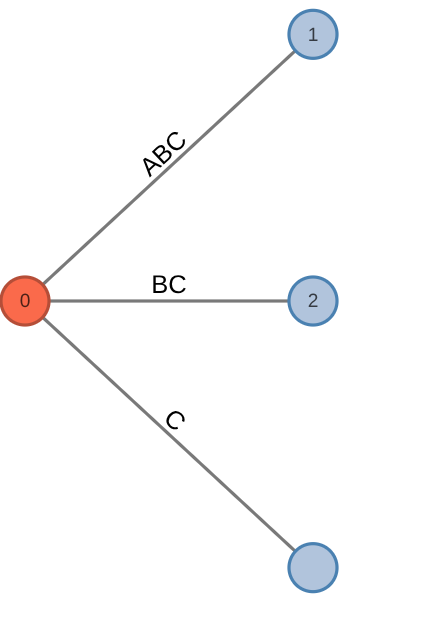 |
- If there exists a path for
ending at position and no edge leaving represents , then the tree must be updated in one of two ways. If is an existing node, then a new leaf is created for character . If is an existing edge, then the edge is split and a new internal node is created with edge .
| Before | After |
|---|---|
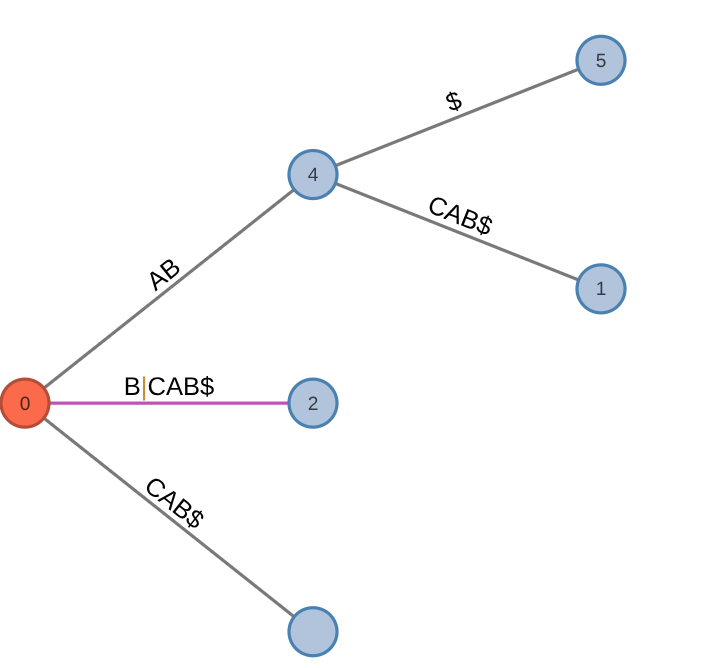 | 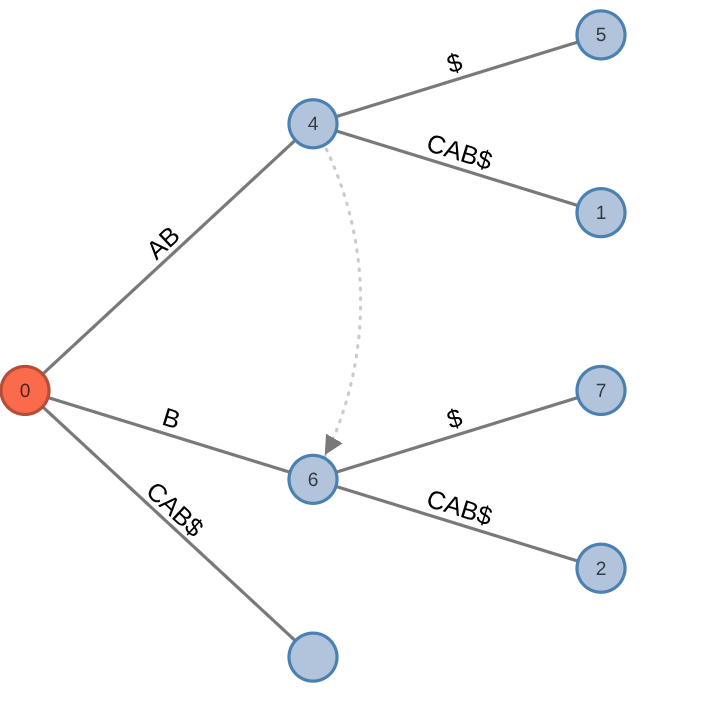 |
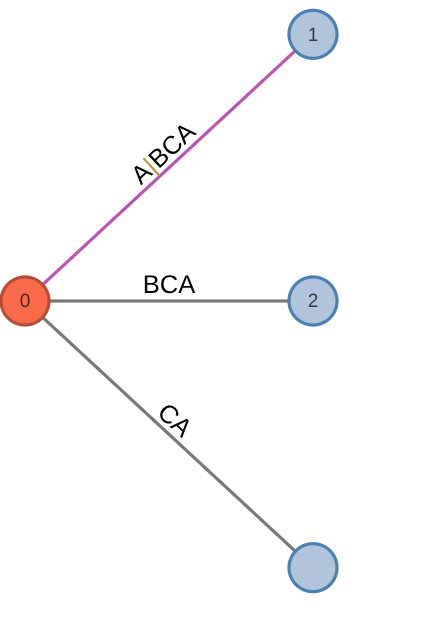
- If the path for the suffix
exists, then the current prefix is already represented by the tree and we do not update the tree. Despite that, we do have to update algorithm metadata, such as the current node and/or the active edge.
| Before | After |
|---|---|
|  |
The notions of suffix and prefix are central to the algorithm at each step. During each phase, the algorithm updates the tree to represent the prefix