LS4 - Microservices
Modern Software Architectures (4 days)
Microservices and state
Messaging systems
The immutable log abstraction
Broker architecture and storage
Replication and fault tolerance
Outline
Monolithic applications
Microservices and decentralized data
Data model and storage engine
- Relational databases, log-structured merge trees (LSM), event logs (more in Kafka section), in-memory cache
Communication styles - Text-based vs binary data exchange formats
- Synchronous (RPC), asynchronous (MQs), pub-sub models
Summary:
-
Decomposing monolithic apps into microservices allows per-microservice database selection
-
Read heavy and write heavy microservices can choose which db to use acording to its needs
-
Microservices improve throughput
-
Microservices allow each service to have its own database
- Data models - relational, document model, key-value
- Storage engine - log-based and B-tree based
-
Microservice communication
- Synchronously (JSON, gRPC)
- Asynchronously (message queues)
- Even-driven pub/sub (Kafka)
Data
Who owns it?
- In monoliths, not as big a problem as all software componetns part of the application
- Updates to data can be done instantly
- Easy foreign key refs, easy joins
Joins reduce data duplication and allow data normalization
- In microservices, data is not bundled as tightly
Scalability
Online traffic is often variable, how do we:
- Support high traffic events (launches, political events)
- Not waste resources during low traffic (pay for compute we don’t use)
Many workloads aim to operate at 60-70% utilization
Scaling:
- Vertical - Make single machines more powerful: +CPU, +DRAM, +network bandwidth
- Reaches a limit eventually
- Horizontal - Add more machines
- This requires a load balancer to operate efficientiently
- Unbounded, and better resource utilization
- Needed for autoscaling
Load balancing:
- Round robin: naive
- Least connections: choose server with fewest active connections
- Least response time: choose server with fastest response time and fewest connections
- Random policy: chosen at random. Useful as a default in uniform/stateless environments
- Weighted distribution: allocate while factoring in server capacity
Problem with this: redeploying a component requires a full application redeploy
- Slow, error prone
We want to decrease coupling between components, to allow teams to work independently:
- Restarting services
- Update their own Table schemas without overhead from other teams
- Evolve independently: choice of programming language, DB schema, DB chosen
Microservices
Smart endpoints connected by dumb pipes
Benefits:
- Improve decoupling, with benefits listen above
Drawbacks: - Data decoupling :(
- No more easy joins
- Now, we must denormalize data and have each microservice “own” the data it needs
Vocab break with SQL:
- Normalized data : Data is stored in separate tables to minimize redundancy
- Denormalized Data : Data is intentionally to multiple tables to reduce the need for joins and improve query performance
- Note they are not opposites
Consistency Guarantees
- Core idea: a microservice owns some data
- Notifies dependent microservices of change
- Soft guarantees on when the updates synchronize
Network Cost
Having to resort to network calls costs you:
- Monoliths: function call is on scale of nanoseconds
- Microservices: RPC call is on scal of microseconds
network protocols?
Summary
Pros:
- Stronger decoupling and lower interdependence
- Improved scalability
- Easier deployment
Cons: - Causes data denormalization
- Network overhead
- Higher complexity
- Debugging complex interactions is harder
Springboot
Framework for creating RESTful microservices
- Reduces boilerplate config code
- Embedded server (Tomcat/Jetty)
Databases
Microservices can have individual DBs
- One microservice may want relational, another might not
SQL (relational DBs):
- MySQL, PostgreSQL, SQLite
NoSQL (non-relational): - Cassandra, Apache HBASE, mongoDB
Summary of LSM tree vs B+ tree:
- LSM trees have higher write throughput
- LSM trees can compress better, B+ trees can cause fragmentation
- B+ trees typically have better read performance
- Key an exist at only one place, unlike LSM trees which involve scanning multiple SSTables
- No clear winner, test on specific use cases
Database Choice Dimensions
Data model
- Format of data user gives to the database
- Ex: Relational, document, graph, key-value
- Shapes query semantics (joins, traversals, etc.)
- Mechanism through which you can retrieve the data
Storage engine
- Mechanism through which you can retrieve the data
- How data is physically stored and indexed
- B-Trees, SSTables, LSM-Trees, Hash Indexes
- Impacts performance tradeoffs (read vs. write performance, range scans, etc.)
Data Model
Relational Databases
- Stores data as tables
- relations through foreign keys and joins
- fixed schema
Document Model - Data is a document
- e.g. JSON, XML
- e.g. MongoDB
- Database mantains this document
- Provides a query language to inspect the contents
- Flexible schema
MongoDB Section
Key-value stores
Simple key-value pairs
- Redis/Memcaches
- Typically operate in-memory only
Usage: - Caching expensive queries
Storage Engine
Log structured storage engines
- Bitcask (for Riak distributed system)
- Apache Cassandra, LevelDB, RocksDB
Page oriented storage engines - Most relational databases - MySQL, etc.
Log Approach to Storing JSON
Naive approach to storing JSON:
- O(1) insert, update, and search
- Offsets to keys stored for search and insert
- Updates are just an append, no actual rewriting
- Previous records immutable
- Offset updated to location of new val
- Compaction:
- Compacts log by periodically removing duplicates
- Runs in background
- Used by Bitcask DB
- Can be expensive
- O(n) search
Limitations of log based approach: - High memory usage for large logs
- Sparce hash index can overcome this limitation but needs sorting
- Has indices typically maintained only for latest log segment
- Range queries not natively supported
- (sorting records can solve this too)
- Compaction can be expensive
Solution: SSTables (memtable) and LSM trees
Log Structured Merge Tree (LSM tree)
designed by google as part of their distributed database BigTable
Components:
- On-disk write-ahead log (WAL)
- In memory sorted tree (memtable)
- Immutable on-disk sorted string table (SSTable)
Core idea: sort in-memory before storing on disk
On disk log provides crash recovery abilities
- System crashes can delete the in-memory sorted tree
- Solution: write out the updates to a log on the disk before inserting into tree
During crash recovery, replay the write-ahead log
Memtable
Properties:
- Maintain a sorted in-memory tree (AVL or red-black tree)
- Write update the in-memory tree
- Write contents from log segment (SSTable) when tree size reaches threshold (typically a few MB)
- Write sorted contents from Memtable to log segment (SSTable) when tree size reaches threshold
- Clear the WAL
SSTables
Properties:
- Immutable logs(like we saw before)
- Updates new records with append with the same key
- Needs compaction to reduce disk footprint
- SSTables specifically:
- Records in ach log is sorted by key (advantages: speeds up compaction)
LSM Properties
Append to on-disk WAL is O(1)
Insert into in-memory memtable (AVL tree) is O(logn)
Eventually, append to on-disk SSTables is O(1) per key
- Bulk write amortizes the disk overhead
On-disk log compaction and merging runs in a background thread
Generally, writes are fast compared to alternative (still, at least 3x write amplification)
Check if key is in the in-memory memtable - O(logn)
If not, scan each of the on-disk SSTables for the key
Generally, reads are slower than writes
B+ Trees
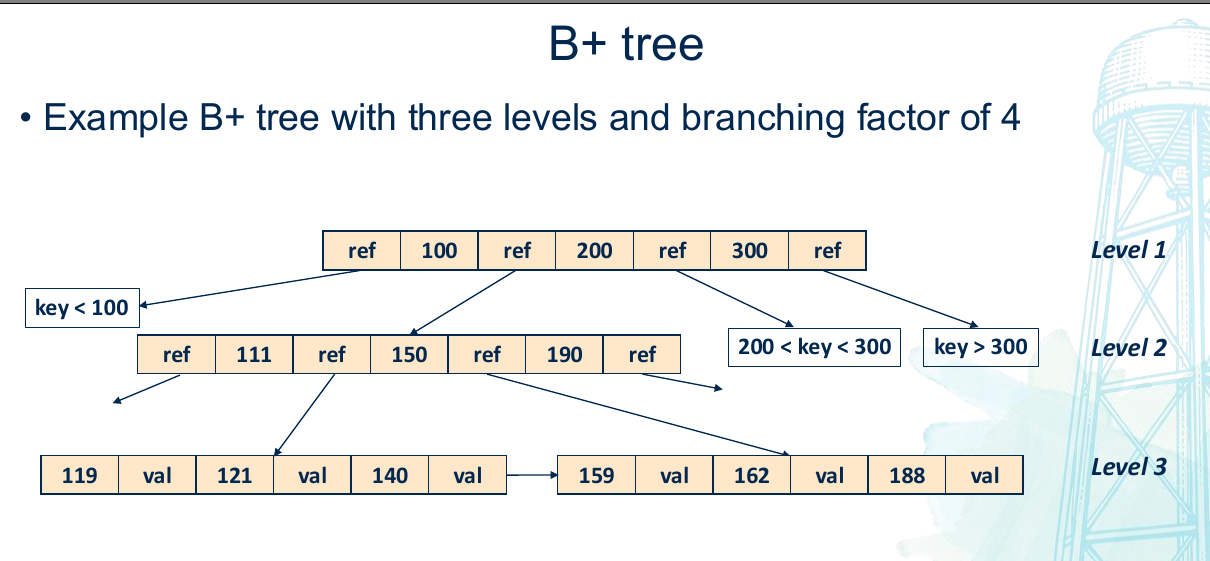
Used to implement primary key indexes in traditional relational databases
On-disk data structure that keeps key-value pairs sorted by key
Supports random accesses
Writes are performed directly on this on-disk sorted tree, unlike in LSM trees which operated on the in-memory Memtable
B+ trees inspired by binary search tree (BST)
- B+ trees have multiple branches
Properties:
- Multiple branches
- Each node has a max and minimum number of keys (branching factor)
- Data only lives in the leaf nodes, intermediary nodes help navigation
- Leaf nodes maintain a linked list for better range scans
- Each node is stored on a ‘page’ of 4KB size
- Traversal follows node pointers until appropriate leaf is reached
- Search is O(logn)
Writes:
- Every B+ tree has a max number of keys per node, if insertion exceeds this max number, the node must be split and tree rebalanced
- Expensive operations performed on disk
Communication Styles
Communication choices:
- Synchronous request/response (JSON over HTTP, gRPC)
- Asynchronous request/response (message queues - RabbitMQ)
- Event-driven publish/subscribe (pub/sub) models
Synchronous
Designed to make a remote call feel like a local function call
Typically blocking
JSON over HTTP, gRPC
JSON
I know enough…
Protobuf
Google binary encoding format