Dataview
LIST
FROM #Collection
WHERE file.name = this.Entry-ForArtificial General Intelligence and the Future of Physics
🎤 Vocab
❗ Information
Similar talk given later: link
✒️ -> Scratch Notes
Scaling Laws
A predictable relationship between compute and performance
- As a side effect, a simple enough law that it was convincing enough to venture capitalists
Constraints to scaling
Power | Chip production | Data scarcity | Latency wall
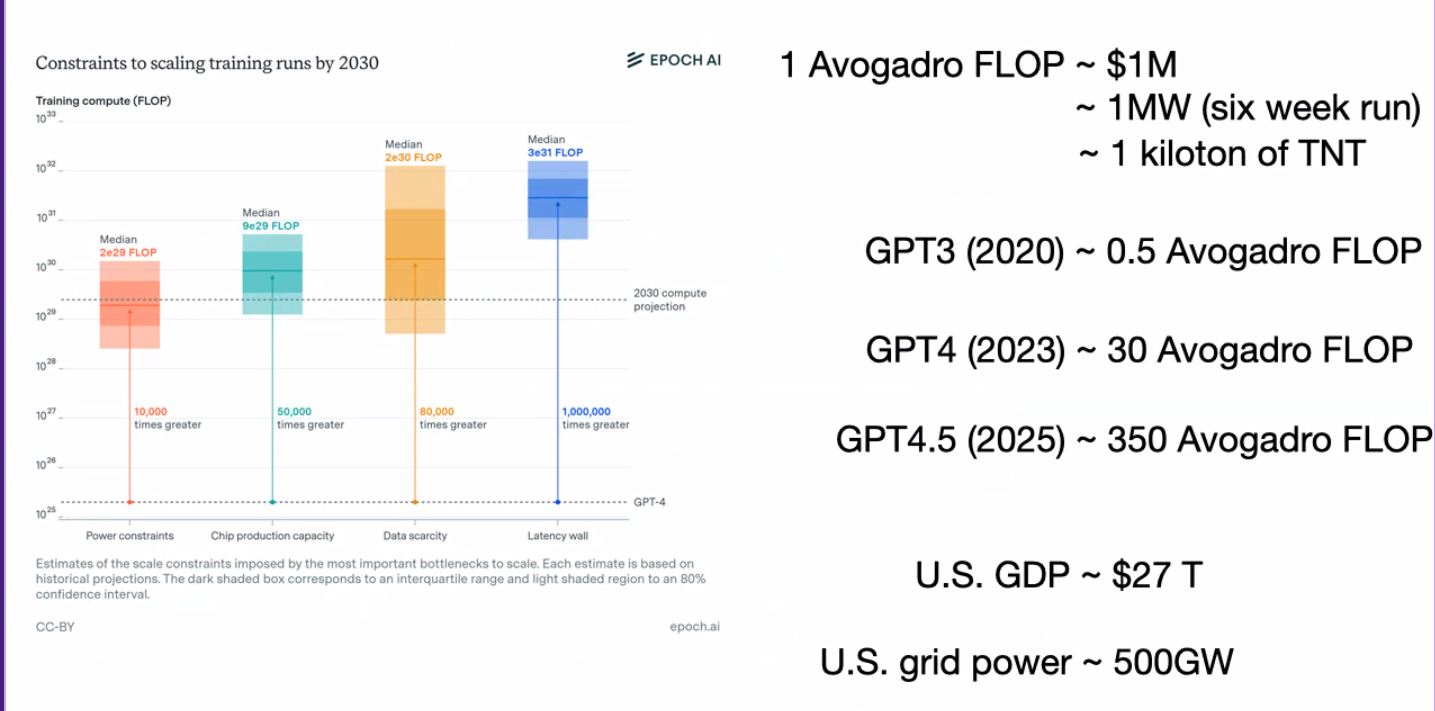
What does more compute help us with?
- MATH Benchmark (2021-2025)
- May 2022 record for LLMs on MATH (high-school maths benchmark): 6%
- Peak Human: ~90% | Lazy grad student: ~40%
- In mid-2022 predicted to get 50%
- Now, in 2025 models are getting near 100%
- What was once SOTA benchmark, is now too easy to be interesting
Techniques to improve reasoning: (used by “Minerva” that got >50% in 2022):
-
TRAIN TIME:
- Scale (bigger neural net)
- Better data (written in TeX, good formatting)
-
INFERENCE TIME:
3) Multi-shot prompting
4) Ask nicely = chain of thought = “think step by step”
- In dawn of LLM testing, prompt engineering was seen as ‘superfluous’, now understood to be highly influential on performance
- Tons of prompts were tested, worst prompt was “Cmon kid, don’t think just do” (Top Gun?)
5) Majority voting
6) tool use (calculator, Mathematic, python, web search)
7) LONG chain of thought
8) Synthetic data
9) Reinforcement Learning (RL) - outcome reward model, process reward model
10) Inference-time MCTS
11) Multimodal (images / audio)
12) Formal verification (e.g. LEAN)
13) “discussion” with >1 LLMs -
GPQA Diamond (2023-2025) (graduate science questions, very hard)
- Designed to be hard, even with googling
- Same scaling seen, accuracy seen improving, and surpassing human levels
- 70% is good human performance, now models approaching 100%
Benchmark Hacking
Instinct might be that models are just scraping the benchmarks online, and learning like that:
- He says not the case, benchmarks sparingly posted onlnie
- Techniques to prevent benchmarks from being included in training data: canary strings
- A string that when seen, is excluded from training data (honor system)
- However, proof that it is not always done (Claude knowing the canary string for BigBench e.g.)


New techniques for improving models
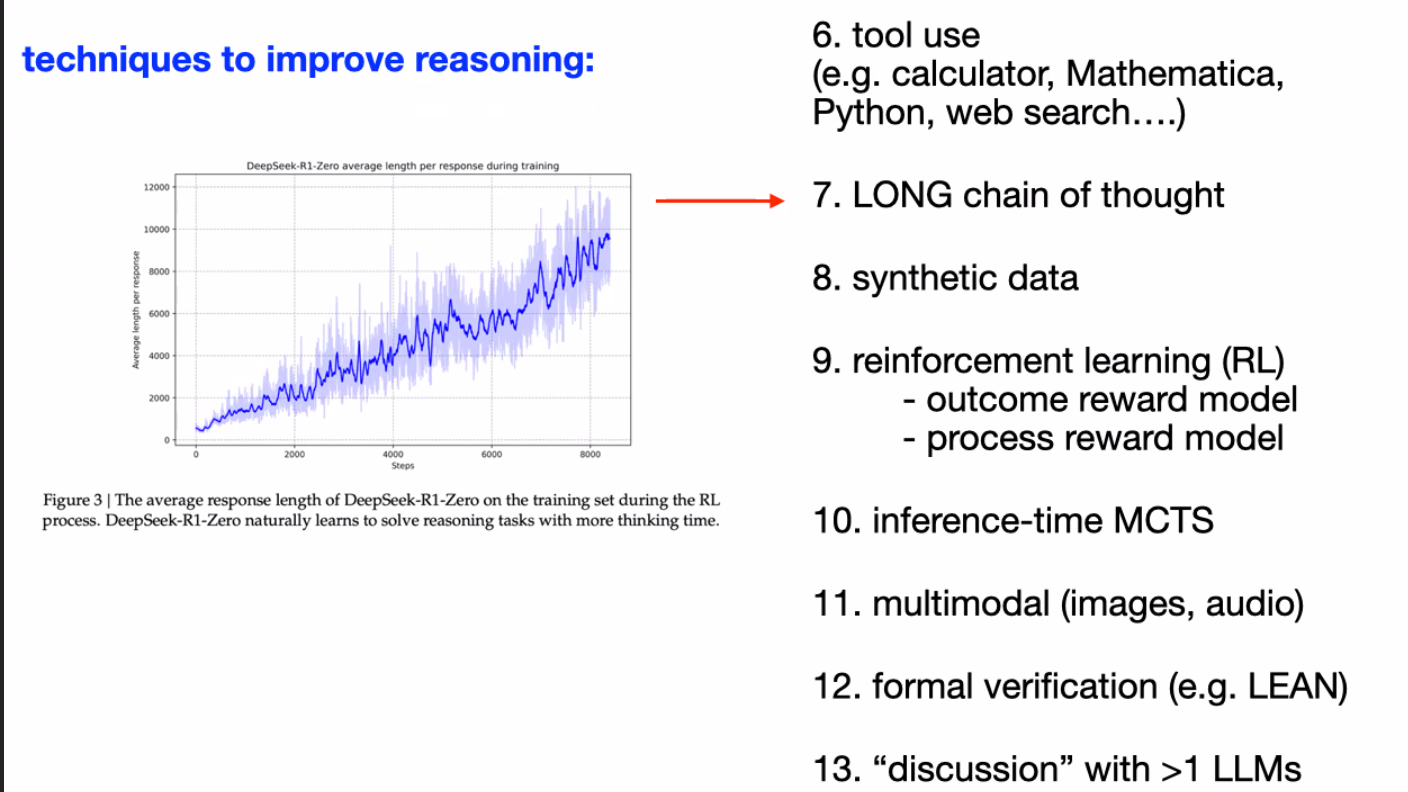
- Can be thought of as “low-hanging fruit” of LLM improvement
- After enabling models with them, massive improvement
Modern SOTA
Try to think of something possible by a remote worker, that can’t be done by an LLM
Math Olympiad

Novel Mathematical Research
“centaur” style
- Human AI collaboration
- A human sets out a goal with somethnig interesting to investigate/prove, and the AI does it
- “The motivic class of the space of genus 0 maps to the flag variety” - arXiv math
- “the kind of insight I would have been proud to produce myself”
- “The motivic class of the space of genus 0 maps to the flag variety” - arXiv math
missed some talk
Future Directions:
(cool images)
The limiting factor is now the manpower to wade through AI slop (his words)
For every groundbreaking paper from AI in physics, what isn’t publicized is the 99 papers of absolute garbage that are produced
See AI as a problem framing problem. If it can be formulated in a way that can be quickly verified without a human in the loop, then it can likely be done wonderfully by AI
On some tasks AI is immensely powerful, and on others it fails completely or subtly. And, unless you use AI a lot, you won’t know which is which.
- Ethan Mollick
- AI is a skill unfortunately, needs to be practiced
Fun commentary:
- In sci-fi, AI is often “locked-up”, and quarantined from humanity
- In real life, we immediately hooked it up to the internet
🔗 -> Links
Resources
- Put useful links here
Connections
- Link all related words