Dataview
LIST
FROM #Collection
WHERE file.name = this.Entry-ForInsert entry name
🎤 Vocab
❗ Information
Small summary
✒️ -> Scratch Notes
Missed the start
Natural Scene Statistics are on the rise
- Stock photography dataset or building their own datasets
- Putting a camera on a cat and letting it walk around lmao
“Our buddies over in computer science”… in relation to building larger datasets
Datasets -
- Things - hebart et al 2019
- Bold - …
- …
Visual Experience Dataset:
- 250 hrs of first person video with head and eye tracking
- ~ 1 image net
- 5-70 years in communities
- (i think this means both adults and children included?)
- Geographic diversity (ME, ND, NV)
Motivation: Why?
We know very little about what the real world looks like
- Natural image statistics
- Dataset bias in CV
We know very little about how we direct our gaze or move our headsrelative to our eyes in the world- Natural gaze distribution across tasks
- Center bias?
Know little about gaze and head behavior as a function of age- Children vs adults?
Summary statistics
- 244+ hrs
- 717 unique sessions
- Average duration: 19 mins
- 49% indoor
- 57% ambulatory
- 58 unique observers
Examples of clips: - To basketball games, museums, lots of cooking, subways, sports, music
- info on eye tracking during music playing!
How?
![]()
Then, do a gaze calibration and validation set
- Fixate on either a 16-25 poi
Challenges
Blinks, false alarms, lighting change, squinting
- Outside, lighting changes are especially frequent
- Can even make people squint
Validated gaze error
Building large image database:
- Get list of terms
- Search and download
- Verify on mTurk
How bias emerges:
- Offensive terms, slang, antiquated terms, subordinate terms
- What who and how things are represented on the internet
- Knowledge, cultural competence
Our author wants to focus on the bias of things present on the internet
- Lived experience isnt cute animals or good food 24/7
- Lived experience is much messier e.g.
To what extent does internet derived visual content reflect lived experience
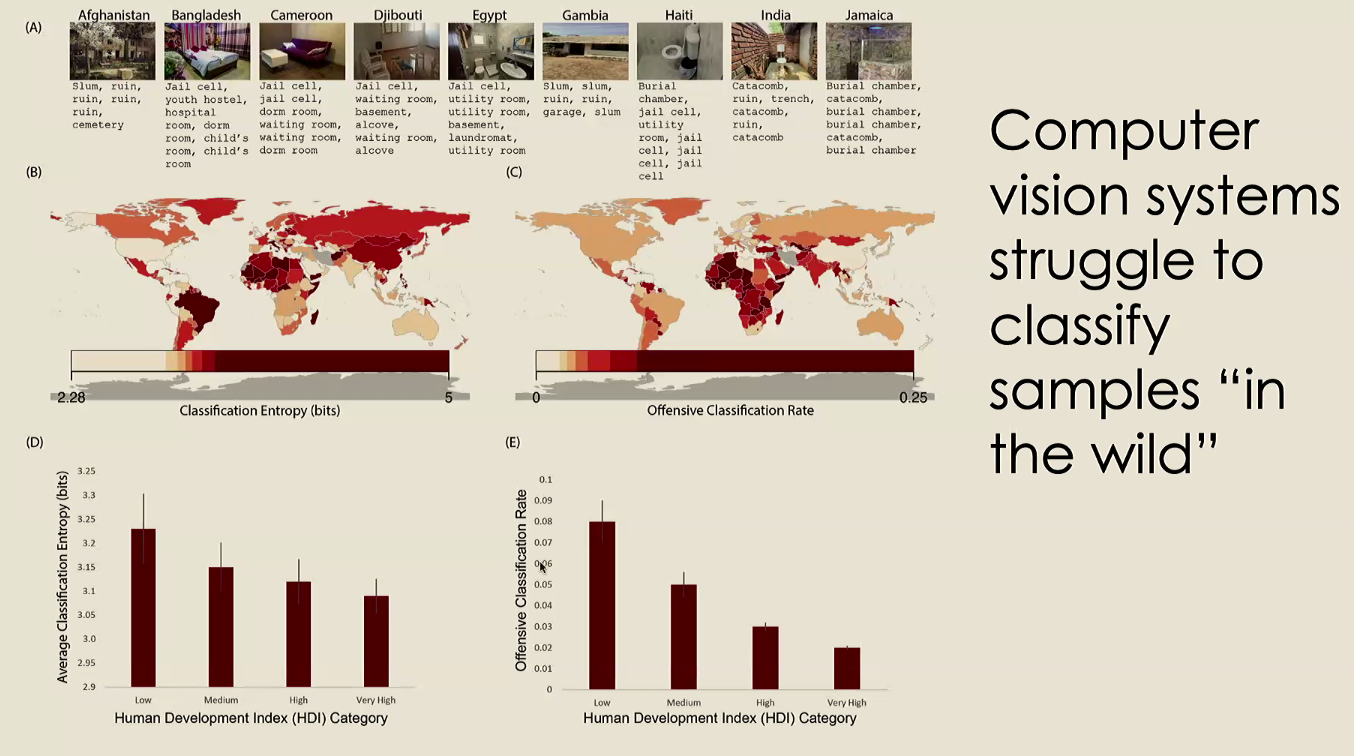
- Submit airbnb photos to pretrained CV models
- Measure how often it gives offensive outputs (“slums”, “jail cell”, etc.)
Methods for measuring network performance
Internet Derived - ADE-20k, Places, SUN
Real - Text, VEDB, PITW
Category Entropy:
- Output of dCNN (deep CNN?), using Alexnet,Resnet-18 and Resnet-50
The performance on internet derived datasets has lower entropy than real life datasets - (entropy being minimized when 1 category is given near 100% prob, min when all categories given equal chance (very unsure))
On top of that, performance on real life is very low as well

What about modern transformers?
GPT-4V has a massive explanatory gap in classification accuracy
Visual Diet of Object Location
Objects tend to be found in different locations preferentially (a lamp usually on a desk)
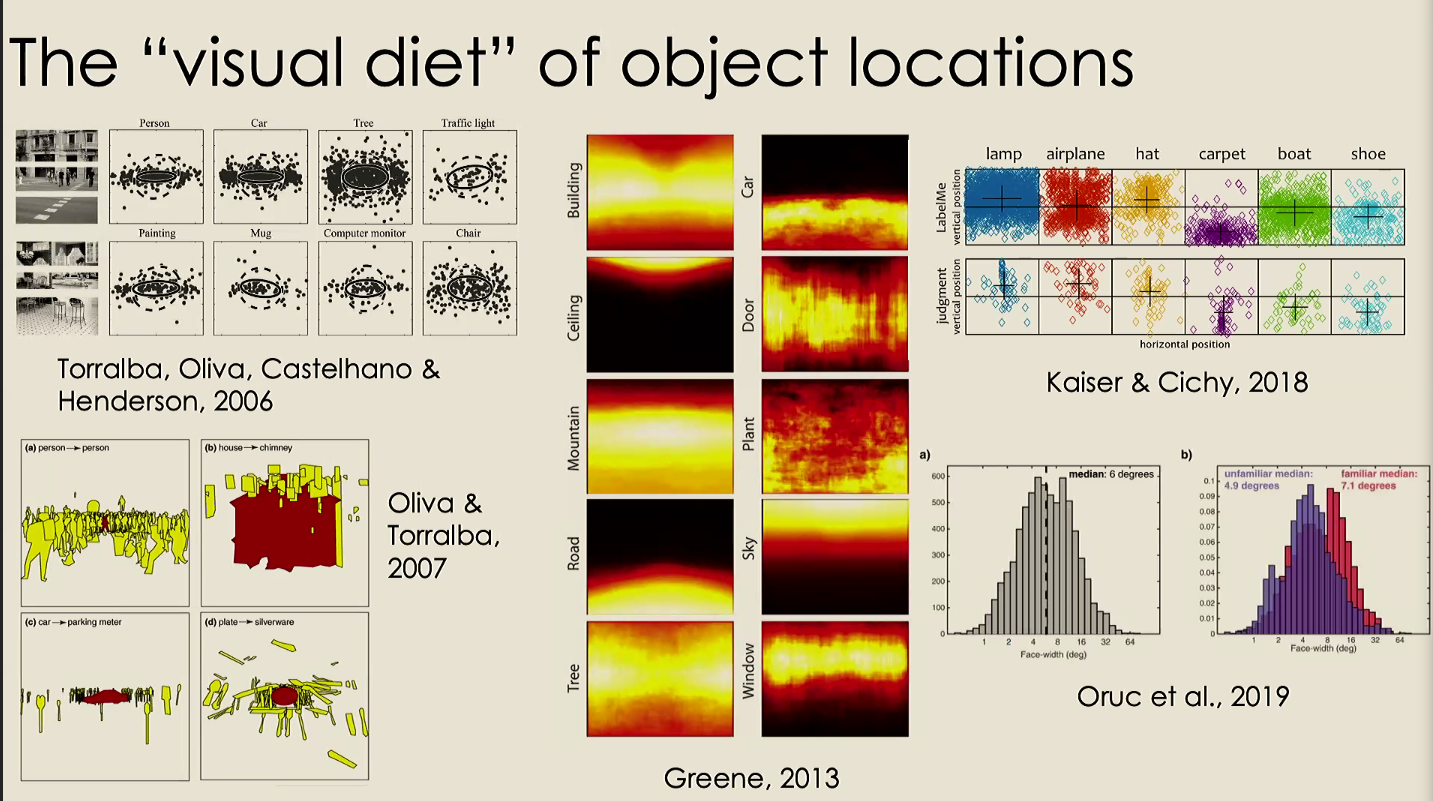
Does ones perspective matter? (being short vs NBA player)? how does this affect gaze?
Using recognition of hands and faces across 27m random frames in datasets
In world centered frame
As you get taller, the location of faces lower in the visual field
As you get taller, the location of hands raise in the visual field
Negative correlation between height and face position
Positive correlation between height and hand position
In gaze centered
Faces get a mild positive correlation
Hands get completely normalized
Prediction
Tall: Less sensitive to face in upper visual field
Short: More sensitive to face in upper visual field
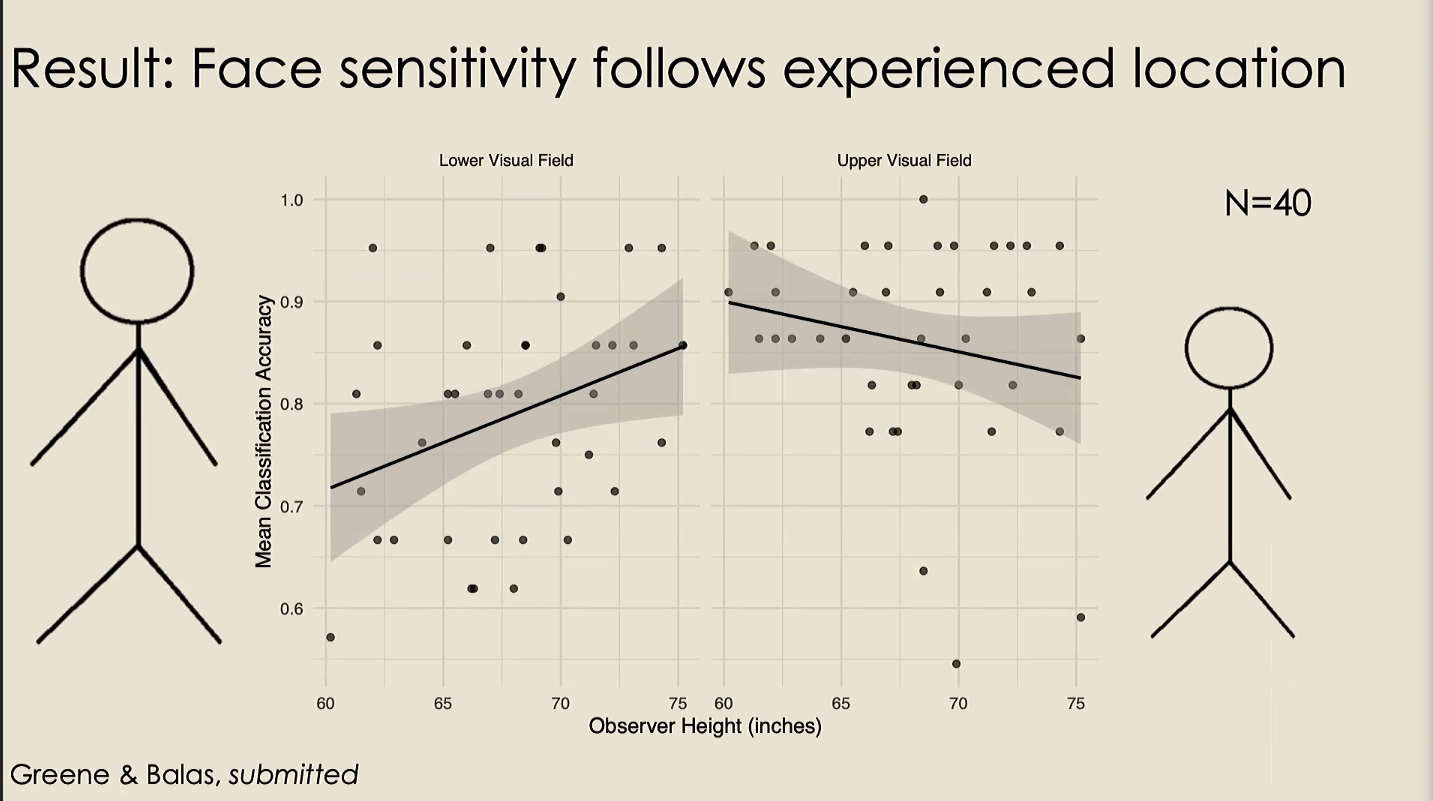
No real effect when experiment done for hands
How to get the Visual Experience Dataset

Also looking into image statistics of seasonal variation
Gaze-contingent image statistics
Q&A
Distortions of fish eyed, have you tried, undistorting?
- Yes, results are identical. Prefer not to do it since lose degrees of freedom
We’re on them damn phones right?
- Fun paper on statistics of minecraft, getting distorted to that?
More within category variance in your scenes than internet scenes right? Maybe that helps in excluding features that don’t matter in classifying a kitchen right?
- Yes and no. The base rate of things represented in the dataset works well. For theirs, it might learn very well about classifying things around campus, but factoring in the base rate of sampling matters and is difficult to account for.
Height effect, what about folks even shorter because they’re in a wheel chair, disabled, etc. ?
- Didn’t exclude based on disabilities or anything like that.
- However, didn’t record either
- Sampling though, research volunteers are overwhelmingly able bodied
- Raises questions about other ways height may change?
- People who do and don’t wear heels?
- Circus performer on stilts?
- Adolescents growing a lot?
How is the sampling working? Are people giving you interesting parts of their day intentionally?
- We thought about it, but decided not to oversample
that?(i think that is phones/computers?) - Blurred out phones lmao (people entering passwords), and isn’t very interesting like that
- Experience dataset is still biased
- No driving, no toilets, etc.
Fixating at floor? Why? Do the children/young participants follow adult gaze patterns?
- Kid participants: we let them ‘pick their own adventure’. They would choose very different thing
- Child data is a lot of coloring/puzzle. Lot of seated sedentary stuff
- Comparisons can be made (to adults doing paint by numbers) but hasn’t been done yet
Looking at floor? Doesn’t reflect the personal experience, why? Peripheral vision, glances, over represented?
- Philosopher of mind call it the grand visual illusion
- Everyone surprised by the poverty of peripheral vision
- Why is their such a poverty of representation of looking at the ground?
- Memorability is kind of ‘inverse compressability’. Nothing particularly memorable about the ground, so we don’t represent/remember as much
- Not sure how to test, but very interesting idea
?
- Stop thinking of scenes as pictures, and more as events coherent in time
- Use peripheral vision to orient head and eyes
Framework of consequences? Differences between an invulnerable robot vs a involved observer?
Bayesian framework, factoring priors? Doing the same thing separated through time, routes?
- Did a similar experiment about walking around a lake once a day for an entire year
- Interesting chronological sampling, but also interesting sampling on saliency (a dog running through the trail more novel than the same tree for the 10th time)
- Overfamiliar environment, not much time needed for navigational tasks?
- UNTRUE, navigational framework still dominates despite being done so much and likely premapped.
- “plan next 10 steps”
- UNTRUE, navigational framework still dominates despite being done so much and likely premapped.
🧪 -> Refresh the Info
Did you generally find the overall content understandable or compelling or relevant or not, and why, or which aspects of the reading were most novel or challenging for you and which aspects were most familiar or straightforward?)
Did a specific aspect of the reading raise questions for you or relate to other ideas and findings you’ve encountered, or are there other related issues you wish had been covered?)
🔗 -> Links
Resources
- Put useful links here
Connections
- Link all related words